はじめに¶
この非常に簡単なケーススタディは、statsmodelsを迅速に稼働させるために設計されています。生データから始めて、統計モデルを推定し、診断プロットを作成するために必要なステップを示します。statsmodelsまたはそのpandasとpatsyの依存関係によって提供される関数のみを使用します。
モジュールと関数のロード¶
statsmodels とその依存関係をインストールした 後、いくつかのモジュールと関数をロードします:
In [1]: import statsmodels.api as sm
In [2]: import pandas
In [3]: from patsy import dmatrices
pandas は numpy 配列に基づいて構築され、豊富なデータ構造とデータ分析ツールを提供します。この pandas.DataFrame 関数は、 R data.frameと同様に、(異種の可能性がある)データのラベル付き配列を提供します。この pandas.read_csv 関数を使用して、カンマ区切り値ファイルを DataFrame オブジェクトに変換できます。
patsy は、統計モデルを記述し、 R 類似の式を使用して計画行列を構築するための Python ライブラリです。
注釈
この例では API インターフェイスを使用します。 API インターフェイス (statsmodels.api と statsmodels.tsa.api)のインポートと、モデルを定義するモジュールからの直接インポートの違いについては、 インポートのパスと構造 を参照してください。
データ¶
アンドレ ミシェル ゲリー による1833 年の「フランスの道徳統計に関する試論」をサポートするために使用された歴史的データコレクションである ゲリー データセット をダウンロードします。データセットは、 Rdataset リポジトリによってカンマ区切り値形式 (CSV) でオンラインでホストされます。ファイルをローカルにダウンロードして、 を使用してロードすることもできますが、 これらすべてが自動的に行われます:
In [4]: df = sm.datasets.get_rdataset("Guerry", "HistData").data
入力/出力ドキュメント ページ には、他のさまざまな形式からインポートする方法が示されています。
関心のある変数を選択し、下の 5 行を確認します:
In [5]: vars = ['Department', 'Lottery', 'Literacy', 'Wealth', 'Region']
In [6]: df = df[vars]
In [7]: df[-5:]
Out[7]:
Department Lottery Literacy Wealth Region
81 Vienne 40 25 68 W
82 Haute-Vienne 55 13 67 C
83 Vosges 14 62 82 E
84 Yonne 51 47 30 C
85 Corse 83 49 37 NaN
Region 列に観測値が 1 つ欠けていることに注意してください。 pandas が提供する DataFrame メソッドを使用してこれを排除します:
In [8]: df = df.dropna()
In [9]: df[-5:]
Out[9]:
Department Lottery Literacy Wealth Region
80 Vendee 68 28 56 W
81 Vienne 40 25 68 W
82 Haute-Vienne 55 13 67 C
83 Vosges 14 62 82 E
84 Yonne 51 47 30 C
実質的な動機とモデル¶
私たちは、フランスの 86 県の識字率が 1820 年代の王立宝くじの一人当たりの賭け金と関連があるかどうかを知りたいと考えています。各部門の富のレベルを制御する必要があります。また、地域の影響による観察されない不均一性を制御するために、回帰式の右側に一連のダミー変数を含めたいと考えています。モデルは、通常の最小二乗回帰 (OLS) を使用して推定されます。
計画行列 ( endog と exog )¶
statsmodels でカバーされているほとんどのモデルに適合するには、2つの設計マトリックスを作成する必要があります。1つ目は内因性変数(すなわち、従属変数、反応変数、回帰変数など)のマトリックスです。2つ目は外因性変数(すなわち、独立変数、予測変数、回帰変数など)のマトリックスです。OLS係数の推定値は通常通り計算されます:
ここで \(y\) は一人当たりの宝くじの賭け金(Lottery)に関するデータの \(N \times 1\) 列です。 \(X\) は \(N \times 7\) で、切片、 Literacy 変数と Wealth 変数、4つの地域バイナリ変数があります。
この patsy モジュールは、 R 類似の式を使用して計画行列を準備する便利な機能を提供します。詳細については、 こちら をご覧ください。
patsy の dmatrices 関数を使用して計画行列を作成します:
In [10]: y, X = dmatrices('Lottery ~ Literacy + Wealth + Region', data=df, return_type='dataframe')
結果の行列/データ フレームは次のようになります:
In [11]: y[:3]
Out[11]:
Lottery
0 41.0
1 38.0
2 66.0
In [12]: X[:3]
Out[12]:
Intercept Region[T.E] Region[T.N] ... Region[T.W] Literacy Wealth
0 1.0 1.0 0.0 ... 0.0 37.0 73.0
1 1.0 0.0 1.0 ... 0.0 51.0 22.0
2 1.0 0.0 0.0 ... 0.0 13.0 61.0
[3 rows x 7 columns]
dmatrices の以下の点に注目してください
カテゴリ 領域 変数を一連の指標変数に分割します。
外因性リグレッサー行列に定数を追加しました。
単純な numpy 配列の代わりに
pandasDataFrameを返しています。 DataFrame ではstatsmodelsが結果をレポートする際メタデータ (変数名など) を引き継ぐことができるため、これは便利です。
もちろん、上記の動作は変更できます。 patsy doc pages を参照してください。
モデルの適合性と概要¶
statsmodels ではモデルを当てはめるに通常、次の 3 つの簡単な手順が必要です:
モデルクラスを使用してモデルを記述する
クラスメソッドを使用してモデルを当てはめる
要約メソッドを使用して結果を検査する
OLS の場合、これは次のようにして実現されます:
In [13]: mod = sm.OLS(y, X) # Describe model
In [14]: res = mod.fit() # Fit model
In [15]: print(res.summary()) # Summarize model
OLS Regression Results
==============================================================================
Dep. Variable: Lottery R-squared: 0.338
Model: OLS Adj. R-squared: 0.287
Method: Least Squares F-statistic: 6.636
Date: Tue, 28 Jan 2025 Prob (F-statistic): 1.07e-05
Time: 00:09:05 Log-Likelihood: -375.30
No. Observations: 85 AIC: 764.6
Df Residuals: 78 BIC: 781.7
Df Model: 6
Covariance Type: nonrobust
===============================================================================
coef std err t P>|t| [0.025 0.975]
-------------------------------------------------------------------------------
Intercept 38.6517 9.456 4.087 0.000 19.826 57.478
Region[T.E] -15.4278 9.727 -1.586 0.117 -34.793 3.938
Region[T.N] -10.0170 9.260 -1.082 0.283 -28.453 8.419
Region[T.S] -4.5483 7.279 -0.625 0.534 -19.039 9.943
Region[T.W] -10.0913 7.196 -1.402 0.165 -24.418 4.235
Literacy -0.1858 0.210 -0.886 0.378 -0.603 0.232
Wealth 0.4515 0.103 4.390 0.000 0.247 0.656
==============================================================================
Omnibus: 3.049 Durbin-Watson: 1.785
Prob(Omnibus): 0.218 Jarque-Bera (JB): 2.694
Skew: -0.340 Prob(JB): 0.260
Kurtosis: 2.454 Cond. No. 371.
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
res オブジェクトには多くの便利な属性があります。たとえば、次のように入力してパラメータ推定値と r 二乗を抽出できます:
In [16]: res.params
Out[16]:
Intercept 38.651655
Region[T.E] -15.427785
Region[T.N] -10.016961
Region[T.S] -4.548257
Region[T.W] -10.091276
Literacy -0.185819
Wealth 0.451475
dtype: float64
In [17]: res.rsquared
Out[17]: np.float64(0.337950869192882)
属性の完全なリストを表示するには、 dir(res) と入力します。
詳細と例については、 回帰のドキュメント ページ を参照してください
診断と仕様テスト¶
statsmodelsを使用すると、さまざまな有用な 回帰診断や仕様テスト を実行できます。たとえば、線形性についてはレインボー テストを適用します (帰無仮説は、関係が線形として適切にモデル化されているということです):
In [18]: sm.stats.linear_rainbow(res)
Out[18]: (np.float64(0.8472339976156916), np.float64(0.6997965543621643))
確かに、上で生成された出力はそれほど冗長ではありませんが、 docstring (または、 print(sm.stats.linear_rainbow.__doc__)) を読むと、最初の数値がF統計量で、2番目の数値がp値であることがわかります。
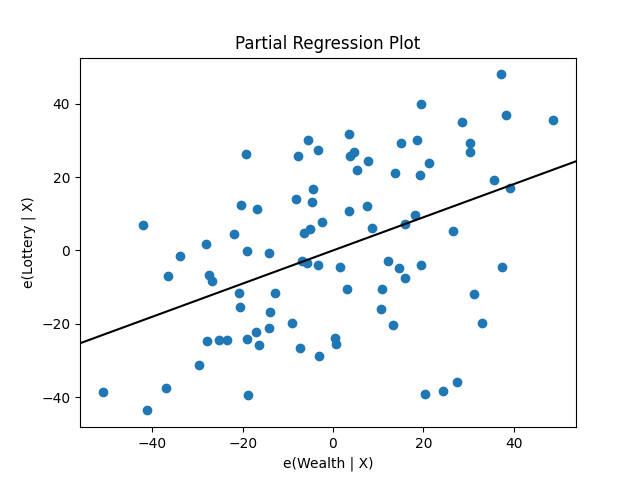
statsmodels はグラフィック機能も提供します。たとえば、次のようにして一連の回帰変数の偏回帰のプロットを描画できます:
In [19]: sm.graphics.plot_partregress('Lottery', 'Wealth', ['Region', 'Literacy'],
....: data=df, obs_labels=False)
....:
Out[19]: <Figure size 640x480 with 1 Axes>
ドキュメンテーション¶
ドキュメントは、IPythonセッションから webdoc を使ってアクセスできます。
ブラウザを開いてオンラインドキュメントを表示します |
もっと¶
おめでとう!目次 の他のトピックに進む準備ができました