ベクトル自己回帰 tsa.vector_ar¶
statsmodels.tsa.vector_ar には、 Vector Autoregressions(VAR) と Vector Error Correction Models(VECM) 使用して複数の時系列を同時にモデリングおよび分析するのに役立つメソッドが含まれています 。
VAR(p) プロセス¶
私たちは \(T\times K\) 多変量時系列 \(Y\) をモデル化することに関心があります。ここで、 \(T\) は観測の数を表し、 \(K\) は変数の数を表します。時系列とそのラグ値との関係を推定する1つの方法は、 ベクトル自己回帰プロセス です:
ここで \(A_i\) は \(K \times K\) 係数行列。
私たちは主に Lutkepohl (2005) の方法と表記法に従っていますが、ここでは説明しません。
モデルフィッティング¶
注釈
以下で参照されているクラスは statsmodels.tsa.api モジュールからアクセスできます。
VARモデルを推定するには、まず同種または構造化されたdtypeの ndarray を使用してモデルを作成する必要があります。構造化配列またはレコード配列を使用する場合、クラスは渡された変数名を使用します。それ以外の場合は、明示的に渡すことができます:
# some example data
In [1]: import numpy as np
In [2]: import pandas
In [3]: import statsmodels.api as sm
In [4]: from statsmodels.tsa.api import VAR
In [5]: mdata = sm.datasets.macrodata.load_pandas().data
# prepare the dates index
In [6]: dates = mdata[['year', 'quarter']].astype(int).astype(str)
In [7]: quarterly = dates["year"] + "Q" + dates["quarter"]
In [8]: from statsmodels.tsa.base.datetools import dates_from_str
In [9]: quarterly = dates_from_str(quarterly)
In [10]: mdata = mdata[['realgdp','realcons','realinv']]
In [11]: mdata.index = pandas.DatetimeIndex(quarterly)
In [12]: data = np.log(mdata).diff().dropna()
# make a VAR model
In [13]: model = VAR(data)
注釈
VAR クラスは、渡された時系列が定常であることを前提としています。非定常またはトレンドデータは、多くの場合、一次微分法やその他の方法によって定常に変換できます。非静止時間系列の直接解析には、標準的な安定VAR(p)モデルは適切ではありません。
実際に推定を行うには、希望するラグ次数を指定して fit メソッドを呼び出します。または、標準の情報基準(下記参照)に基づいてモデルにラグ次数を選択させることもできます:
In [14]: results = model.fit(2)
In [15]: results.summary()
Out[15]:
Summary of Regression Results
==================================
Model: VAR
Method: OLS
Date: Tue, 28, Jan, 2025
Time: 00:09:22
--------------------------------------------------------------------
No. of Equations: 3.00000 BIC: -27.5830
Nobs: 200.000 HQIC: -27.7892
Log likelihood: 1962.57 FPE: 7.42129e-13
AIC: -27.9293 Det(Omega_mle): 6.69358e-13
--------------------------------------------------------------------
Results for equation realgdp
==============================================================================
coefficient std. error t-stat prob
------------------------------------------------------------------------------
const 0.001527 0.001119 1.365 0.172
L1.realgdp -0.279435 0.169663 -1.647 0.100
L1.realcons 0.675016 0.131285 5.142 0.000
L1.realinv 0.033219 0.026194 1.268 0.205
L2.realgdp 0.008221 0.173522 0.047 0.962
L2.realcons 0.290458 0.145904 1.991 0.047
L2.realinv -0.007321 0.025786 -0.284 0.776
==============================================================================
Results for equation realcons
==============================================================================
coefficient std. error t-stat prob
------------------------------------------------------------------------------
const 0.005460 0.000969 5.634 0.000
L1.realgdp -0.100468 0.146924 -0.684 0.494
L1.realcons 0.268640 0.113690 2.363 0.018
L1.realinv 0.025739 0.022683 1.135 0.257
L2.realgdp -0.123174 0.150267 -0.820 0.412
L2.realcons 0.232499 0.126350 1.840 0.066
L2.realinv 0.023504 0.022330 1.053 0.293
==============================================================================
Results for equation realinv
==============================================================================
coefficient std. error t-stat prob
------------------------------------------------------------------------------
const -0.023903 0.005863 -4.077 0.000
L1.realgdp -1.970974 0.888892 -2.217 0.027
L1.realcons 4.414162 0.687825 6.418 0.000
L1.realinv 0.225479 0.137234 1.643 0.100
L2.realgdp 0.380786 0.909114 0.419 0.675
L2.realcons 0.800281 0.764416 1.047 0.295
L2.realinv -0.124079 0.135098 -0.918 0.358
==============================================================================
Correlation matrix of residuals
realgdp realcons realinv
realgdp 1.000000 0.603316 0.750722
realcons 0.603316 1.000000 0.131951
realinv 0.750722 0.131951 1.000000
matplotlib を使用してデータを視覚化する方法がいくつかあります。
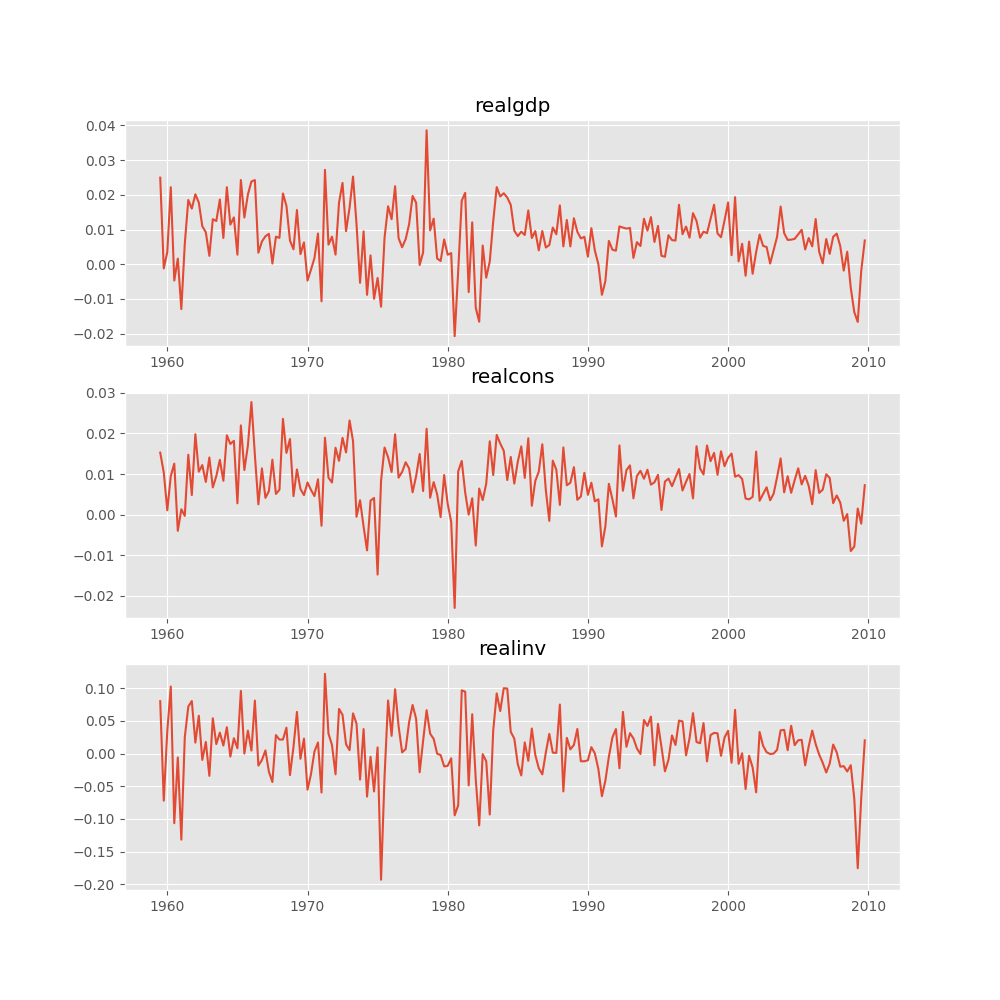
入力時系列をプロットする:
In [16]: results.plot()
Out[16]: <Figure size 1000x1000 with 3 Axes>
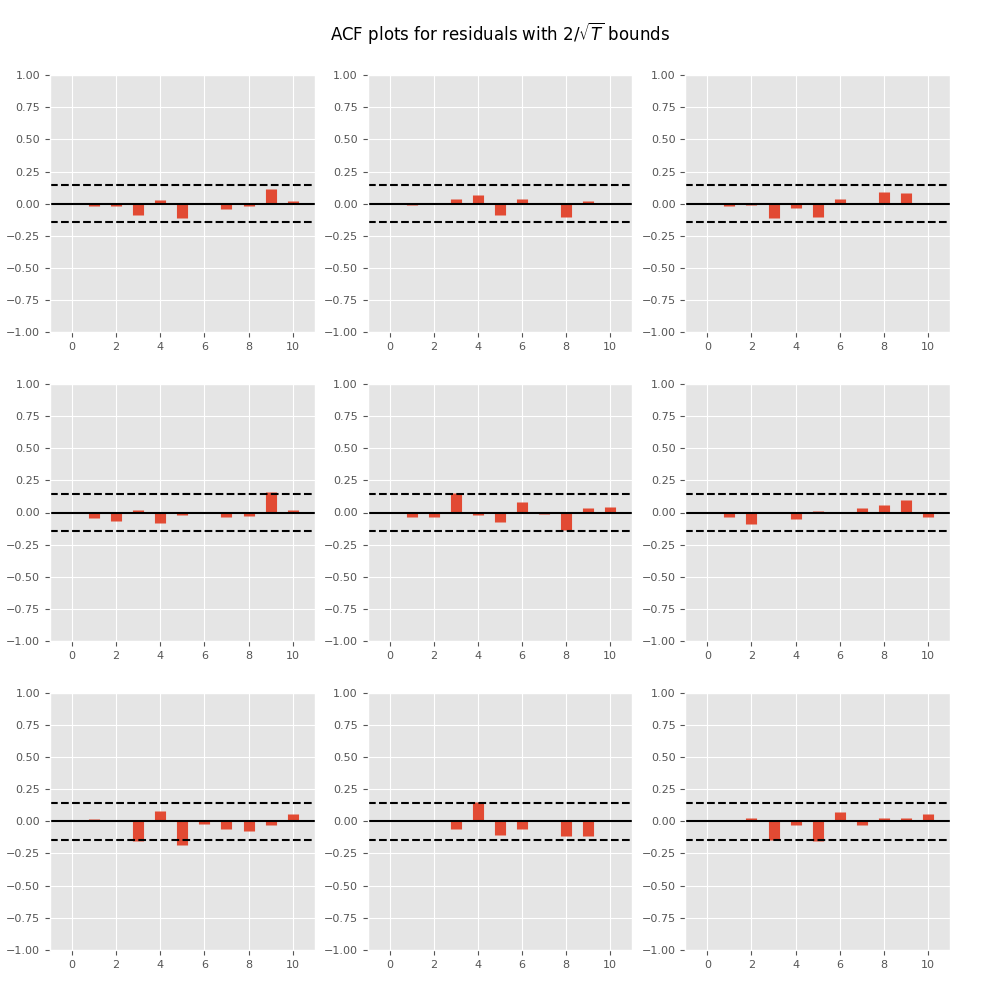
時系列自己相関関数のプロット:
In [17]: results.plot_acorr()
Out[17]: <Figure size 1000x1000 with 9 Axes>
ラグ次数の選択¶
遅延順序の選択は難しい問題になる可能性があります。標準分析では、尤度検定または情報基準に基づく順序選択を採用しています。私たちは後者を実装しており、 VAR クラスを通じてアクセスできます:
In [18]: model.select_order(15)
Out[18]: <statsmodels.tsa.vector_ar.var_model.LagOrderResults at 0x7fe3ed8dd630>
fit 関数を呼び出す際には、ラグの最大数と次数の選択に使用する次数の基準を渡すことができます:
In [19]: results = model.fit(maxlags=15, ic='aic')
予測¶
線形予測子は、平均二乗誤差に関する最適な h ステップ先の予測です:
この予測を生成するには、 forecast を使用できます。予測の "初期値" を指定する必要があることに注意してください:
In [20]: lag_order = results.k_ar
In [21]: results.forecast(data.values[-lag_order:], 5)
Out[21]:
array([[ 0.0062, 0.005 , 0.0092],
[ 0.0043, 0.0034, -0.0024],
[ 0.0042, 0.0071, -0.0119],
[ 0.0056, 0.0064, 0.0015],
[ 0.0063, 0.0067, 0.0038]])
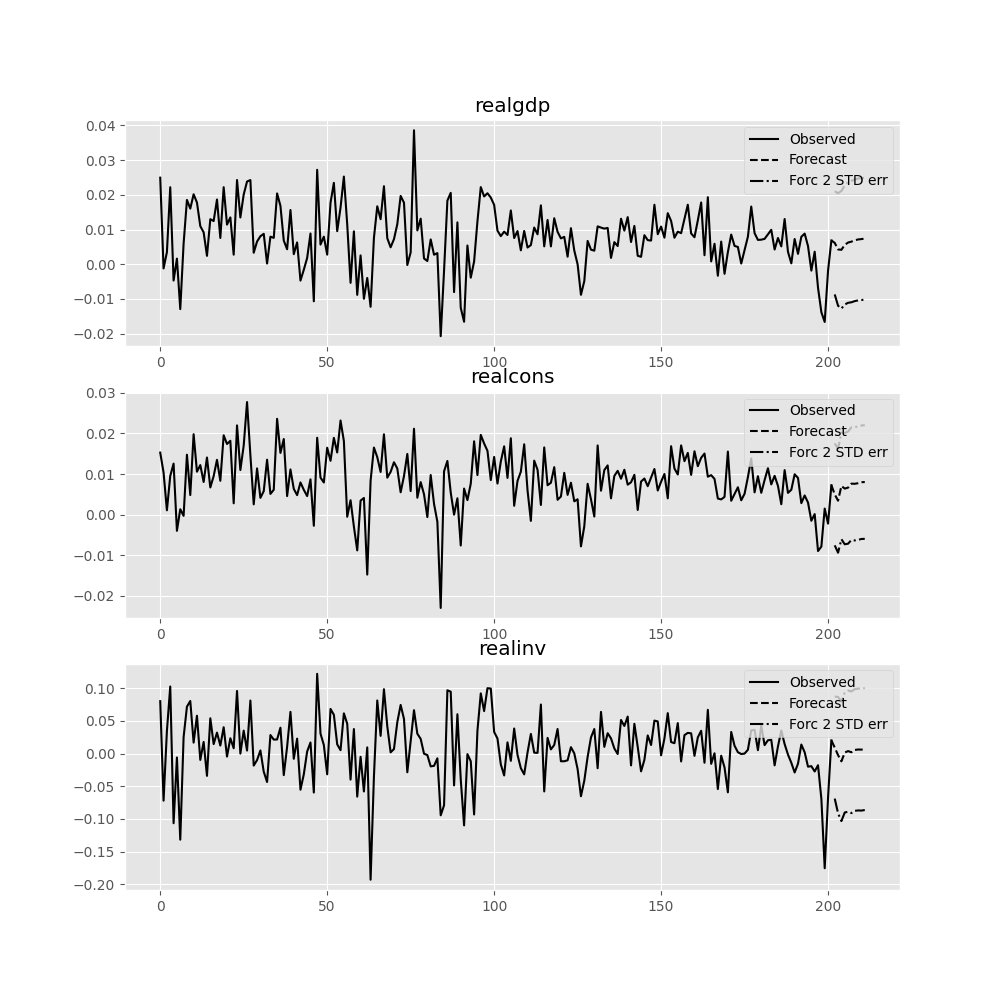
forecast_interval 関数は、漸近的な標準誤差とともに上記の予測を生成します。これらは plot_forecast 関数を使用して可視化できます:
In [22]: results.plot_forecast(10)
Out[22]: <Figure size 1000x1000 with 3 Axes>
クラスリファレンス¶
|
VAR(p) プロセスを適合させ、ラグ次数の選択を行う |
|
クラスは既知の VAR(p) プロセスを表します |
|
固定のラグ次数で VAR(p) プロセスを推定する |
推定後の分析¶
ベクトル自己回帰過程に対しては、いくつかのプロセス特性と推定後の付加的な結果が利用できます。
|
モデルのラグ次数を選択するための結果クラス。 |
|
仮説検定の結果クラス。 |
|
非正規性の Jarque-Bera テストの結果クラス。 |
|
残差自己相関のかばん検定の結果クラス。 |
インパルス応答解析¶
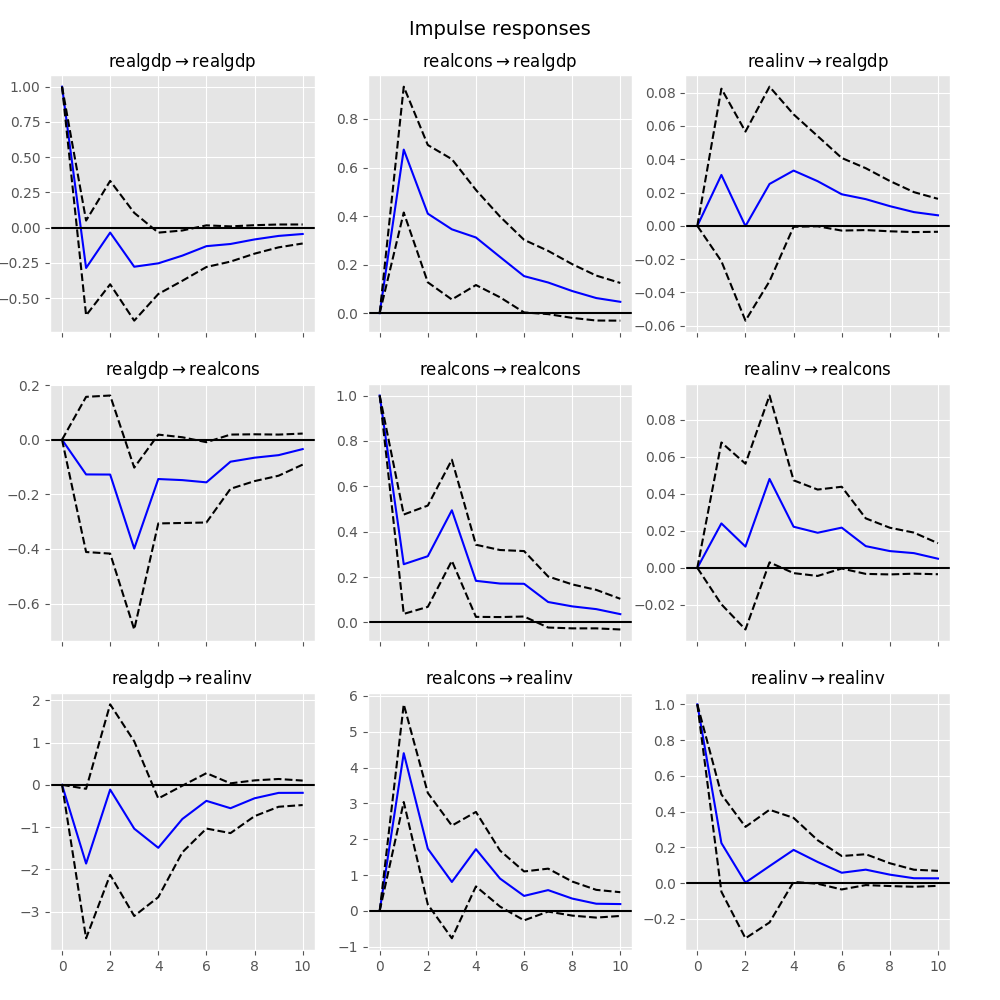
インパルス応答 は計量経済研究において興味深いものです。これらは、変数の1つにおける単位インパルスに対する推定応答です。実際には、VAR(p)プロセスのMA( \(\infty\) )表現を使用して計算されます:
VARResults オブジェクトに対して irf を呼び出すことで、インパルス応答解析を実行できます:
In [23]: irf = results.irf(10)
これらは、プロット関数を使用して、直交形式または非直交形式で視覚化できます。漸近標準誤差はデフォルトで 95 % の有意水準でプロットされますが、これはユーザーが変更できます。
注釈
直交化は、推定誤差共分散行列 \(\hat \Sigma_u\) のコレスキー分解を使用して行われます。したがって、変数の順序に応じて解釈が変わる可能性があります。
In [24]: irf.plot(orth=False)
Out[24]: <Figure size 1000x1000 with 9 Axes>
プロット関数は柔軟であり、必要に応じて関心のある変数のみをプロットできることに注意してください:
In [25]: irf.plot(impulse='realgdp')
Out[25]: <Figure size 1000x1000 with 3 Axes>
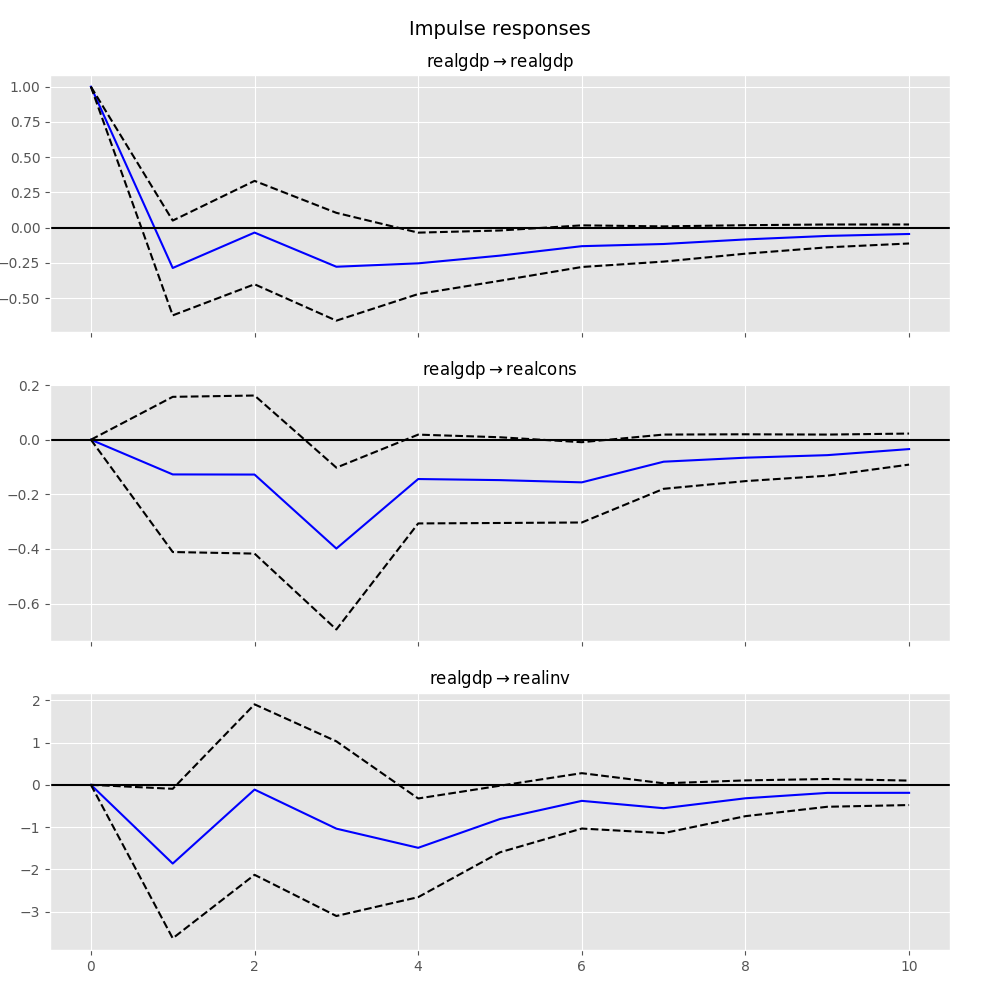
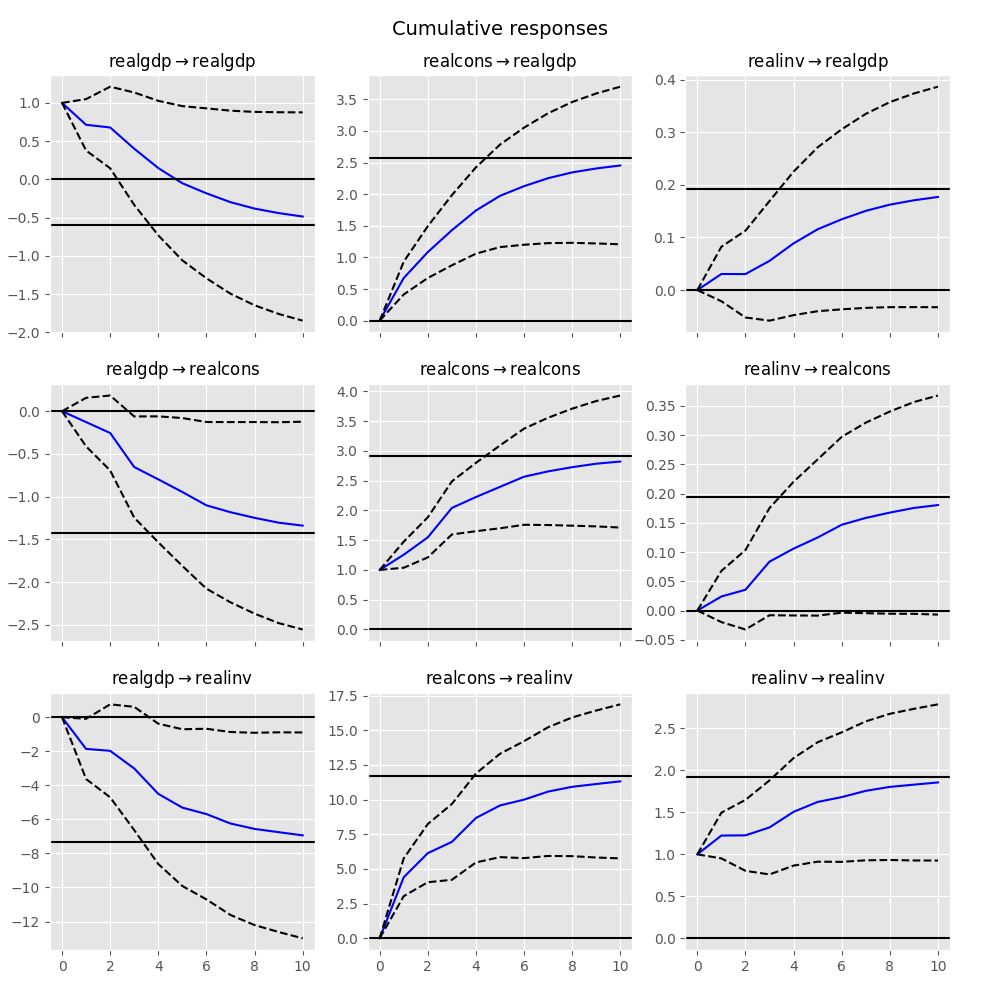
累積効果 \(\Psi_n=\sum_{i=0}^n\Phi_i\) は、以下のように長期効果とともにプロットできます:
In [26]: irf.plot_cum_effects(orth=False)
Out[26]: <Figure size 1000x1000 with 9 Axes>
|
インパルス応答解析クラス。 |
予測誤差分散分解 (FEVD)¶
i-step-ahead予測におけるk上の要素jの予測誤差は、直交化されたインパルス応答 \(\Theta_i\) を使って分解できます:
これらは、 fevd 機能を使用して、合計ステップ数まで計算されます:
In [27]: fevd = results.fevd(5)
In [28]: fevd.summary()
FEVD for realgdp
realgdp realcons realinv
0 1.000000 0.000000 0.000000
1 0.864889 0.129253 0.005858
2 0.816725 0.177898 0.005378
3 0.793647 0.197590 0.008763
4 0.777279 0.208127 0.014594
FEVD for realcons
realgdp realcons realinv
0 0.359877 0.640123 0.000000
1 0.358767 0.635420 0.005813
2 0.348044 0.645138 0.006817
3 0.319913 0.653609 0.026478
4 0.317407 0.652180 0.030414
FEVD for realinv
realgdp realcons realinv
0 0.577021 0.152783 0.270196
1 0.488158 0.293622 0.218220
2 0.478727 0.314398 0.206874
3 0.477182 0.315564 0.207254
4 0.466741 0.324135 0.209124
返された FEVD オブジェクトを通して視覚化することもできます:
In [29]: results.fevd(20).plot()
Out[29]: <Figure size 1000x1000 with 3 Axes>
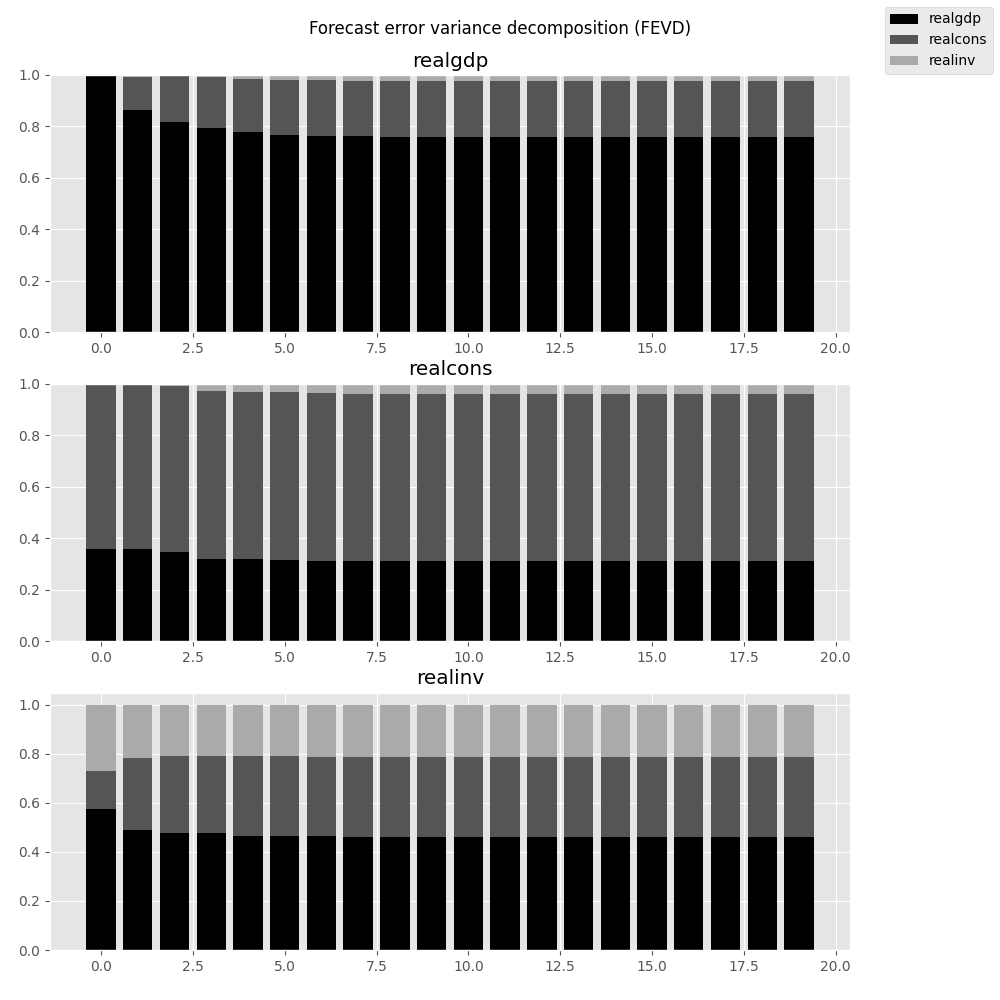
|
予測誤差分散分解と漸近標準誤差の計算とプロット |
統計的検定¶
モデルの結果に関する仮説検定や、モデルの仮定の妥当性(正規性、誤差の白色性/ "独立同分布性"i など)を実行するために、多くの異なる方法が提供されている。
グレンジャーの因果関係¶
ある変量または変量のグループが別の変量に対して「因果的」であるかどうか、「因果的」の定義に関心を持つことがよくあります。VARモデルの文脈では、変数の集合はVAR方程式の1つの中でグレンジャー因果的であると言えます。グレンジャー因果性の数学や定義については詳しく説明しませんが、読者にお任せします。 wald オブジェクトには、VARResults( \(\chi^2\) )テストまたはFテストを実行するための test_causality メソッドがあります。
In [30]: results.test_causality('realgdp', ['realinv', 'realcons'], kind='f')
Out[30]: <statsmodels.tsa.vector_ar.hypothesis_test_results.CausalityTestResults at 0x7fe3ed44c520>
正規性¶
このドキュメントの冒頭で指摘したように、ホワイトノイズ成分 \(u_t\) は正規分布していると仮定されています。この仮定は、パラメータ推定値が一貫しているか漸近的正規性を満たすために必要ではありませんが、結果は一般に、残差がガウスホワイトノイズである有限サンプルの方が信頼性が高くなります。この仮定がデータセットと一致しているかどうかを検定するために、 VARResults は test_normality メソッドを提供しています。
In [31]: results.test_normality()
Out[31]: <statsmodels.tsa.vector_ar.hypothesis_test_results.NormalityTestResults at 0x7fe3ed2a9300>
残差の白色性¶
推定残差の白色性(これは有意な残差自己相関がないことを意味します)を検定するために、 VARResults の test_whiteness メソッドを使うことができます。
|
仮説検定の結果クラス。 |
|
グレンジャー因果性および瞬時的因果性の結果クラス。 |
|
非正規性の Jarque-Bera テストの結果クラス。 |
|
残差自己相関のかばん検定の結果クラス。 |
構造ベクトルの自己回帰¶
いくつかのタイプの構造 VaRモデルを処理するクラスのマッチングセットがあります。
|
VAR を当てはめてから、次のように定義される A と B の構造コンポーネントを推定します: |
|
クラスは既知の SVAR(p) プロセスを表します |
|
固定のラグ次数で VAR(p) プロセスを推定する |
ベクトル誤り訂正モデル (VECM)¶
ベクトル誤差補正モデルは、1つ以上の永続的な確率的トレンド(単位根)からの短期的な偏差を研究するために使用されます。VECMは、確率的トレンドの仮定された数によって暗示される構造を課すことによって、時系列のベクトルの差をモデル化します。 VECM は、これらのモデルを指定し推定するために使用されます。
VECM(\(k_{ar}-1\)) の形式は以下のとおりです
ここで
これは [1] の第7章に記述されているとおりです。
決定論的な項を持つVECM( \(k_{ar}-1\) )の形式は以下のとおりです
\(D^{co}_{t-1}\) には、共和分関係の内部にある(または共和分関係に限定された)決定論的な項があります。 \(\eta\) は対応する推定量です。共和分関係の内部に決定論的な項を渡すには、 exog_coint 引数を使うことができます。切片と線形トレンドの2つの特殊なケースでは、これらの項を宣言するもっと簡単な方法があります。すなわち、それぞれ deterministic 引数に "ci" と "li" を渡すことができます。したがって、共和分関係の内部の切片では、 deterministic として "ci" を渡すか、 endog 引数として data が渡された場合に exog_coint として np.ones(len(data)) を渡すことができます。これにより、すべての \(t\) に対して \(D_{t-1}^{co}=1\) が保証されます。
共和分関係の外で決定論的な項を使うこともできます。これらは上の式の \(D_t\) で定義され、対応する推定量は行列 \(C\) で定義されています。そのような項は exog 引数に渡すことで指定します。切片や線形トレンドに対しては、再び`決定論的`を代わりに使う可能性があります。切片に対しては "co" を渡し、線形トレンドに対しては "lo" を渡します。ここで o は outside を表します。
次の表は、 [2] で検討された5つのケースを示しています。最後の列は、これらのケースごとに deterministic 引数に渡す文字列を示しています。
ケース |
切片 |
Slope of the linear trend |
決定論的 |
|---|---|---|---|
I |
0 |
0 |
|
II |
\(- \alpha \beta^T \mu\) |
0 |
|
III |
\(\neq 0\) |
0 |
|
IV |
\(\neq 0\) |
\(- \alpha \beta^T \gamma\) |
|
V |
\(\neq 0\) |
\(\neq 0\) |
|
|
ベクトル誤り訂正モデル (VECM) を表すクラス。 |
|
Johansen の共和分検定の結果クラス |
|
Johansen の共和分検定の結果クラス |
|
利用可能な情報基準のそれぞれに基づいてラグ次数の選択を計算します。 |
|
VECM の共和分ランクを計算します。 |
|
ベクトル誤差修正モデル (VECM) の推定関連の結果を保持するクラス。 |
|
共和分ランク検定結果を保持するクラス。 |