ハードルモデルおよび切断カウントモデル¶
著者: Josef Perktold
Statsmodelsは現在、バージョン 0.14 で追加されたハードルモデルおよび切断カウントモデルをサポートしています。
ハードルモデルは、ゼロのモデルとゼロより大きいカウントの分布モデルで構成されています。ゼロモデルは、ゼロ対ゼロより大きいというバイナリモデルです。非ゼロカウントのカウントモデルは、ゼロ切断カウントモデルです。
Statsmodels は現在、ゼロモデルおよびカウントモデルとして、ポアソン分布および負の二項分布をサポートしています。Logit、Probit、またはGLM-Binomialなどのバイナリモデルは、ゼロモデルとしてはまだサポートされていません。 ポアソン-ポアソンハードルの利点は、標準的なポアソンモデルが両方のモデルでパラメータが等しい特殊ケースであることです。これにより、ポアソンモデルに対するハードルモデルの簡単なウォルド検定が提供されます。
実装されたバイナリモデルは右切断モデルで、観測値は 1 で右切断されています。つまり、0 または 1 のカウントのみが観測されます。
ハードルモデルは、ゼロ切断データに対してゼロモデルとカウントモデルを個別に推定することで推定できます。これらの観測は独立して分布していると仮定されています(観測間に相関はない)。パラメータ推定の結果として得られる共分散行列は、サブモデルによって与えられた対角ブロックを持つブロック対角行列です。ジョイント推定はまだ実装されていません。
切断および切断カウントモデルは主にハードルモデルをサポートするために開発されました。ただし、左切断カウントモデルにはハードルモデルをサポートする以外にも用途があります。右切断モデルは、GLM-Binomial、Logit、またはProbitによってモデル化できるバイナリ観測値のみをサポートするため、独立した関心を持ちません。
ハードルモデルには、サブモデルの分布をオプションとして含む単一のクラス「HurdleCountModel」があります。 切断モデルのクラスは現在、「TruncatedLFPoisson」と「TruncatedLFNegativeBinomialP」であり、ここで「LF」は固定の観測値に依存しない切断点での左切断を意味します。
[ ]:
[1]:
import numpy as np
import pandas as pd
import statsmodels.discrete.truncated_model as smtc
from statsmodels.discrete.discrete_model import (
Poisson, NegativeBinomial, NegativeBinomialP, GeneralizedPoisson)
from statsmodels.discrete.count_model import (
ZeroInflatedPoisson,
ZeroInflatedGeneralizedPoisson,
ZeroInflatedNegativeBinomialP
)
from statsmodels.discrete.truncated_model import (
TruncatedLFPoisson,
TruncatedLFNegativeBinomialP,
_RCensoredPoisson,
HurdleCountModel,
)
ハードルモデルのシミュレーション¶
ポアソン-ポアソン ハードル モデルを明示的にシミュレートしている理由は、そのための分布ヘルパー関数がまだ存在しないためです。
[2]:
np.random.seed(987456348)
# large sample to get strong results
nobs = 5000
x = np.column_stack((np.ones(nobs), np.linspace(0, 1, nobs)))
mu0 = np.exp(0.5 *2 * x.sum(1))
y = np.random.poisson(mu0, size=nobs)
print(np.bincount(y))
y_ = y
indices = np.arange(len(y))
mask = mask0 = y > 0
for _ in range(10):
print( mask.sum())
indices = mask #indices[mask]
if not np.any(mask):
break
mu_ = np.exp(0.5 * x[indices].sum(1))
y[indices] = y_ = np.random.poisson(mu_, size=len(mu_))
np.place(y, mask, y_)
mask = np.logical_and(mask0, y == 0)
np.bincount(y)
[102 335 590 770 816 739 573 402 265 176 116 59 35 7 11 4]
4898
602
93
11
2
0
[2]:
array([ 102, 1448, 1502, 1049, 542, 234, 81, 31, 6, 5])
誤って指定されたポアソンモデルの推定¶
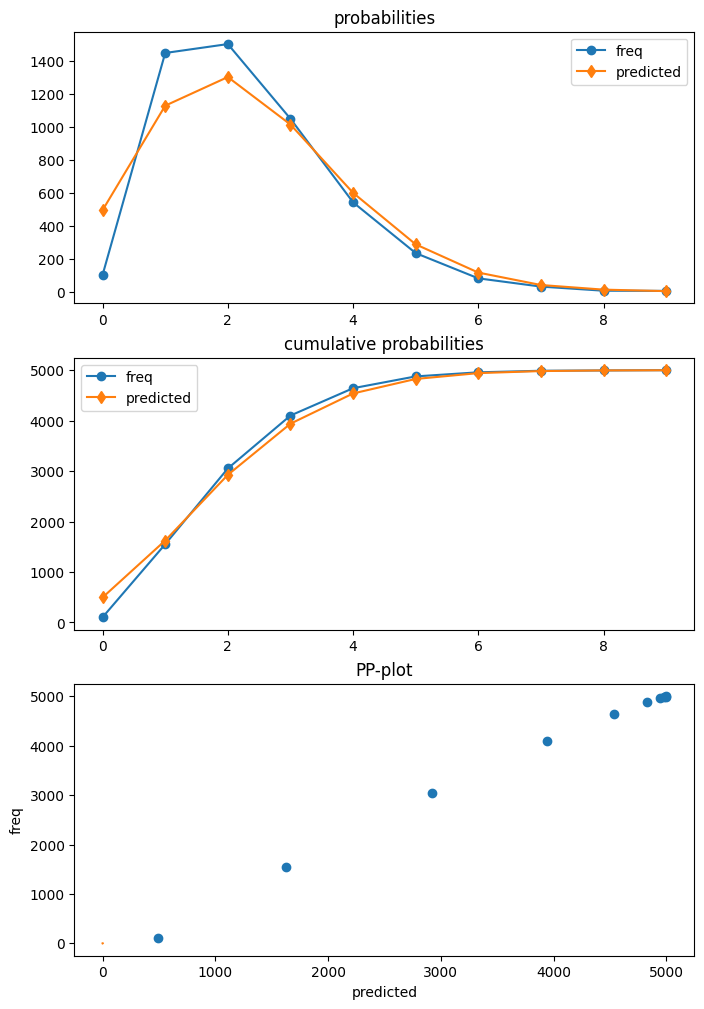
生成したデータにはゼロデフレーションがあり、つまり、ポアソンモデルで予想されるよりも少ないゼロが観測されます。
モデルをフィッティングした後、ポアソン診断クラスのプロット関数を使用して、予想される予測分布と実現された頻度を比較できます。これは、ポアソン モデルがゼロの数を過大評価し、1 と 2 の数を過小評価していることを示しています。
[3]:
mod_p = Poisson(y, x)
res_p = mod_p.fit()
print(res_p.summary())
Optimization terminated successfully.
Current function value: 1.668079
Iterations 4
Poisson Regression Results
==============================================================================
Dep. Variable: y No. Observations: 5000
Model: Poisson Df Residuals: 4998
Method: MLE Df Model: 1
Date: Thu, 28 Nov 2024 Pseudo R-squ.: 0.008678
Time: 23:10:27 Log-Likelihood: -8340.4
converged: True LL-Null: -8413.4
Covariance Type: nonrobust LLR p-value: 1.279e-33
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
const 0.6532 0.019 33.642 0.000 0.615 0.691
x1 0.3871 0.032 12.062 0.000 0.324 0.450
==============================================================================
[4]:
dia_p = res_p.get_diagnostic()
dia_p.plot_probs();
ハードルモデルの推定¶
次に、正しく指定されたポアソン-ポアソンハードルモデルを推定します。
HurdleCountModelのシグネチャとオプションを見ると、ポアソン-ポアソンがデフォルトであることがわかりますので、このモデルを作成する際に特別なオプションを指定する必要はありません。
HurdleCountModel(endog, exog, offset=None, dist='poisson', zerodist='poisson', p=2, pzero=2, exposure=None, missing='none', **kwargs)
HurdleCountModelの結果クラスにはget_diagnosticメソッドがあります。しかし、現在利用可能な診断メソッドは一部に限られています。予測分布のプロットは、データとの非常に高い一致を示しています。
[5]:
mod_h = HurdleCountModel(y, x)
res_h = mod_h.fit(disp=False)
print(res_h.summary())
HurdleCountModel Regression Results
==============================================================================
Dep. Variable: y No. Observations: 5000
Model: HurdleCountModel Df Residuals: 4996
Method: MLE Df Model: 2
Date: Thu, 28 Nov 2024 Pseudo R-squ.: 0.01503
Time: 23:10:29 Log-Likelihood: -8004.9
converged: [True, True] LL-Null: -8127.1
Covariance Type: nonrobust LLR p-value: 8.901e-54
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
zm_const 0.9577 0.048 20.063 0.000 0.864 1.051
zm_x1 1.0576 0.121 8.737 0.000 0.820 1.295
const 0.5009 0.024 20.875 0.000 0.454 0.548
x1 0.4577 0.039 11.882 0.000 0.382 0.533
==============================================================================
[6]:
dia_h = res_h.get_diagnostic()
dia_h.plot_probs();
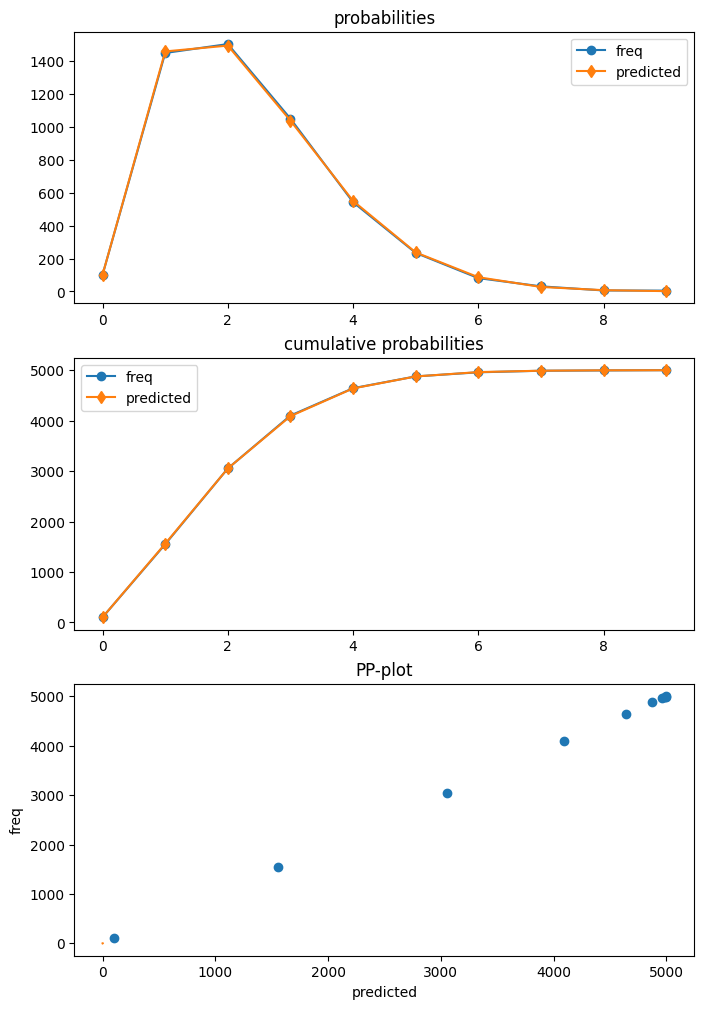
Wald検定を使用して、ゼロ・モデルのパラメータがゼロで切り捨てられたカウント・モデルのパラメータと同じであるかどうかを検定できます。p値は非常に小さく、モデルが単なるポアソンであることを正しく否定します。大きなサンプル・サイズを使用しているため、この場合、検定の検出力は大きくなります。
[7]:
res_h.wald_test("zm_const = const, zm_x1 = x1", scalar=True)
[7]:
<class 'statsmodels.stats.contrast.ContrastResults'>
<Wald test (chi2): statistic=470.67320745809684, p-value=6.231772790219687e-103, df_denom=2>
予測¶
ハードルモデルは、全体のモデルおよび2つのサブモデルの統計量に対して予測を行うために使用できます。予測すべき統計量は、whichキーワードを使用して指定します。
以下は、predictのドックストリングから取られたもので、利用可能なオプションをリストしています。
which : str(オプション)
予測する統計量。デフォルトは 'mean'。
- 'mean' : 従属変数の条件付き期待値 E(y | x)
- 'mean-main' : 切断されたカウントモデルの平均パラメータ。
これは切断された分布の平均ではないことに注意してください。
- 'linear' : 切断されたカウントモデルの線形予測子。
- 'var' : モデルによって示唆された従属変数の推定分散を返します。
- 'prob-main' : メインモデルが選ばれる確率。これは非ゼロカウントを観測する確率 P(y > 0 | x) です。
- 'prob-zero' : ゼロカウントを観測する確率。P(y=0 | x)。
これは ``1 - prob-main`` と等しいです。
- 'prob-trunc' : 切断カウントモデルの切断確率。
これは切断モデルによって示唆されたゼロカウントを観測する確率です。
- 'mean-nonzero' : 観測がゼロより大きい条件での期待値、E(y | X, y>0)
- 'prob' : 各カウントの確率(0からmax(endog)まで)、または提供された場合はy_valuesに対する確率。
これは多変量の戻り値です(複数の観測に対して予測する場合は2次元)。
これらのオプションは、predictおよびget_predictionメソッドの結果クラスで使用できます。
以下の例では、元のデータから等間隔で取得した説明変数のセットを作成します。その後、これらの説明変数に条件付けて利用可能な統計量を予測できます。
[8]:
which_options = ["mean", "mean-main", "linear", "mean-nonzero", "prob-zero", "prob-main", "prob-trunc", "var", "prob"]
ex = x[slice(None, None, nobs // 5), :]
ex
[8]:
array([[1. , 0. ],
[1. , 0.20004001],
[1. , 0.40008002],
[1. , 0.60012002],
[1. , 0.80016003]])
[9]:
for w in which_options:
print(w)
pred = res_h.predict(ex, which=w)
print(" ", pred)
mean
[1.89150663 2.07648059 2.25555158 2.43319456 2.61673457]
mean-main
[1.65015181 1.8083782 1.98177629 2.17180081 2.38004602]
linear
[0.50086729 0.59243042 0.68399356 0.77555669 0.86711982]
mean-nonzero
[2.04231955 2.16292424 2.29857565 2.45116551 2.62277411]
prob-zero
[0.07384394 0.0399661 0.01871771 0.00733159 0.00230273]
prob-main
[0.92615606 0.9600339 0.98128229 0.99266841 0.99769727]
prob-trunc
[0.19202076 0.16391977 0.1378242 0.11397219 0.09254632]
var
[1.43498239 1.51977118 1.63803729 1.7971727 1.99738345]
prob
[[7.38439416e-02 3.63208532e-01 2.99674608e-01 1.64836199e-01
6.80011882e-02 2.24424568e-02 6.17224344e-03 1.45501981e-03
3.00125448e-04 5.50280612e-05]
[3.99660987e-02 3.40376213e-01 3.07764462e-01 1.85518182e-01
8.38717591e-02 3.03343722e-02 9.14266959e-03 2.36191491e-03
5.33904431e-04 1.07277904e-04]
[1.87177088e-02 3.10869602e-01 3.08037002e-01 2.03486809e-01
1.00816333e-01 3.99590837e-02 1.31983274e-02 3.73659033e-03
9.25635762e-04 2.03822556e-04]
[7.33159258e-03 2.77316512e-01 3.01138113e-01 2.18003999e-01
1.18365316e-01 5.14131777e-02 1.86098635e-02 5.77384524e-03
1.56745522e-03 3.78244503e-04]
[2.30272798e-03 2.42169151e-01 2.88186862e-01 2.28632665e-01
1.36039066e-01 6.47558475e-02 2.56869828e-02 8.73374304e-03
2.59833880e-03 6.87129546e-04]]
[10]:
for w in which_options[:-1]:
print(w)
pred = res_h.get_prediction(ex, which=w)
print(" ", pred.predicted)
print(" se", pred.se)
mean
[1.89150663 2.07648059 2.25555158 2.43319456 2.61673457]
se [0.07877461 0.05693768 0.05866892 0.09551274 0.15359057]
mean-main
[1.65015181 1.8083782 1.98177629 2.17180081 2.38004602]
se [0.03959242 0.03164634 0.02471869 0.02415162 0.03453261]
linear
[0.50086729 0.59243042 0.68399356 0.77555669 0.86711982]
se [0.04773779 0.03148549 0.02960421 0.04397859 0.06453261]
mean-nonzero
[2.04231955 2.16292424 2.29857565 2.45116551 2.62277411]
se [0.02978486 0.02443098 0.01958745 0.0196433 0.02881753]
prob-zero
[0.07384394 0.0399661 0.01871771 0.00733159 0.00230273]
se [0.00918583 0.00405155 0.00220446 0.00158494 0.00090255]
prob-main
[0.92615606 0.9600339 0.98128229 0.99266841 0.99769727]
se [0.00918583 0.00405155 0.00220446 0.00158494 0.00090255]
prob-trunc
[0.19202076 0.16391977 0.1378242 0.11397219 0.09254632]
se [0.00760257 0.00518746 0.00340683 0.00275261 0.00319587]
var
[1.43498239 1.51977118 1.63803729 1.7971727 1.99738345]
se [0.04853902 0.03615054 0.02747485 0.02655145 0.03733328]
C:\Users\user\projects\statsmodels-main\statsmodels\base\_prediction_inference.py:782: UserWarning: using default log-link in get_prediction
warnings.warn("using default log-link in get_prediction")
オプションwhich="prob"は、予測された確率の配列をexogの各行について返します。私たちはしばしば、すべてのexogに対して平均された確率に関心があります。予測メソッドには、観測値を跨いで予測値の平均を計算し、その平均予測に対する対応する標準誤差と信頼区間を求めるオプションaverage=Trueがあります。
[11]:
pred = res_h.get_prediction(ex, which="prob", average=True)
print(" ", pred.predicted)
print(" se", pred.se)
[2.84324139e-02 3.06788002e-01 3.00960210e-01 2.00095571e-01
1.01418732e-01 4.17809876e-02 1.45620174e-02 4.41222267e-03
1.18509193e-03 2.86300514e-04]
se [2.81472153e-03 5.00830805e-03 1.37524761e-03 1.87343644e-03
1.99068656e-03 1.23878529e-03 5.78099178e-04 2.21180110e-04
7.25021181e-05 2.08872555e-05]
読みやすい表示を得るために、pandas DataFrame を使用します。 「predicted」 列には、exog の 5 つのグリッド ポイントの平均応答値の予測分布の確率質量関数が表示されます。観測された数よりも大きいカウントは確率が正であり、表に含まれていないため、確率の合計は 1 になりませんが、この例ではその確率は小さいです。
[12]:
dfp_h = pred.summary_frame()
dfp_h
[12]:
| predicted | se | ci_lower | ci_upper | |
|---|---|---|---|---|
| 0 | 0.028432 | 0.002815 | 0.022916 | 0.033949 |
| 1 | 0.306788 | 0.005008 | 0.296972 | 0.316604 |
| 2 | 0.300960 | 0.001375 | 0.298265 | 0.303656 |
| 3 | 0.200096 | 0.001873 | 0.196424 | 0.203767 |
| 4 | 0.101419 | 0.001991 | 0.097517 | 0.105320 |
| 5 | 0.041781 | 0.001239 | 0.039353 | 0.044209 |
| 6 | 0.014562 | 0.000578 | 0.013429 | 0.015695 |
| 7 | 0.004412 | 0.000221 | 0.003979 | 0.004846 |
| 8 | 0.001185 | 0.000073 | 0.001043 | 0.001327 |
| 9 | 0.000286 | 0.000021 | 0.000245 | 0.000327 |
[13]:
prob_larger9 = pred.predicted.sum()
prob_larger9, 1 - prob_larger9
[13]:
(np.float64(0.9999215487936677), np.float64(7.84512063323195e-05))
get_prediction はこの場合、基本の PredictionResultsDelta クラスのインスタンスを返します。
標準誤差、p値、複数の分布パラメータに依存する非線形関数の信頼区間などの推論統計は、デルタ法を使用して計算されます。予測に関する推論は、正規分布に基づいて行われます。
[14]:
pred
[14]:
<statsmodels.base._prediction_inference.PredictionResultsDelta at 0x25e367f1b10>
[15]:
pred.dist, pred.dist_args
[15]:
(<scipy.stats._continuous_distns.norm_gen at 0x25e31018d60>, ())
ハードルモデルによって予測された分布と、以前に推定したポアソンモデルによって予測された分布を比較できます。最後の列「diff」では、ポアソンモデルが観測値の約 8% でゼロの数を過大評価し、1 および 2 のカウントをそれぞれ 7%、3.7% 過小評価していることが示されています。これはexogグリッド上での平均値に基づいています。
[16]:
pred_p = res_p.get_prediction(ex, which="prob", average=True)
dfp_p = pred_p.summary_frame()
dfp_h["poisson"] = dfp_p["predicted"]
dfp_h["diff"] = dfp_h["poisson"] - dfp_h["predicted"]
dfp_h
[16]:
| predicted | se | ci_lower | ci_upper | poisson | diff | |
|---|---|---|---|---|---|---|
| 0 | 0.028432 | 0.002815 | 0.022916 | 0.033949 | 0.107848 | 0.079416 |
| 1 | 0.306788 | 0.005008 | 0.296972 | 0.316604 | 0.237020 | -0.069768 |
| 2 | 0.300960 | 0.001375 | 0.298265 | 0.303656 | 0.263523 | -0.037437 |
| 3 | 0.200096 | 0.001873 | 0.196424 | 0.203767 | 0.197657 | -0.002439 |
| 4 | 0.101419 | 0.001991 | 0.097517 | 0.105320 | 0.112511 | 0.011093 |
| 5 | 0.041781 | 0.001239 | 0.039353 | 0.044209 | 0.051833 | 0.010052 |
| 6 | 0.014562 | 0.000578 | 0.013429 | 0.015695 | 0.020124 | 0.005561 |
| 7 | 0.004412 | 0.000221 | 0.003979 | 0.004846 | 0.006769 | 0.002356 |
| 8 | 0.001185 | 0.000073 | 0.001043 | 0.001327 | 0.002012 | 0.000827 |
| 9 | 0.000286 | 0.000021 | 0.000245 | 0.000327 | 0.000537 | 0.000250 |
その他の事後分析¶
推定されたハードルモデルは、パラメータのウォルド検定や予測に使用できます。また、対数尤度値や情報量基準などの他の最尤統計量も利用可能です。
ただし、推定、パラメータ推定、予測に必要ない補助関数を必要とするいくつかの事後分析方法はまだ利用できません。現在サポートされていない主な方法は、score_test、get_distribution、およびget_influenceです。get_diagnosticsの診断指標は、予測に基づいた統計量にのみ利用可能です。
[17]:
res_h.llf, res_h.df_resid, res_h.aic, res_h.bic
[17]:
(np.float64(-8004.904002793644),
4996,
np.float64(16017.808005587289),
np.float64(16043.876778352953))
過剰な分散はありますか?モデルが正しく指定されていれば、ピアソン残差を使用してピアソンのカイ二乗統計量を計算でき、この値は1に近くなるべきです。
[18]:
(res_h.resid_pearson**2).sum() / res_h.df_resid
[18]:
np.float64(0.9989670114949286)
診断クラスには、診断プロットで使用される予測分布もあります。現在、他の統計やテストは利用できません。
[19]:
dia_h.probs_predicted.mean(0)
[19]:
array([0.02044612, 0.29147174, 0.29856288, 0.20740118, 0.10990976,
0.04737579, 0.0172898 , 0.00548983, 0.00154646, 0.00039214])
[20]:
res_h.resid[:10]
[20]:
array([ 1.10849337, 1.10830496, -0.89188344, -0.89207183, 1.10773978,
-0.8924486 , -0.89263697, 0.10717466, 0.1069863 , 0.10679794])
[ ]: