事後分析の概要 - ポアソンモデル¶
このノートブックでは、いくつかのモデルで利用可能な事後分析結果の概要を、ポアソンモデルを例に示します。
詳細については、https://github.com/statsmodels/statsmodels/issues/7707 を参照してください。
従来、モデルの結果クラスはウォルド推論と予測を提供していました。現在、いくつかのモデルには、推論、予測、仕様検定または診断検定のための事後分析結果を得るための追加のメソッドがあります。
以下は、主に離散モデル向けの最大尤度モデルに関する現在のパターンに基づいています。他のモデルは、いくつかの点で異なるAPIパターンに従っています。OLSやWLSのような線形モデルは、例えばOLSの影響など、特別な実装を持っています。GLMもモデル特有の機能をいくつか持っています。
主な事後分析機能は以下の通りです:
推論 - ウォルド検定 セクション
推論 - スコア検定 セクション
get_prediction推測統計を使用した予測 セクションget_distribution推定されたパラメータに基づく分布クラス セクションget_diagnostic診断および仕様検定、指標、グラフ セクションget_influence外れ値および影響診断 セクション
シミュレーション例¶
図では、正しく指定され、比較的大きな標本を持つポアソン回帰のデータをシミュレートします。1 つの回帰変数は 2 つのレベルを持つカテゴリ変数であり、2 番目の回帰変数は単位間隔で均一に分布しています。
[1]:
import numpy as np
import pandas as pd
from scipy import stats
import matplotlib.pyplot as plt
from statsmodels.discrete.discrete_model import Poisson
from statsmodels.discrete.diagnostic import PoissonDiagnostic
[2]:
np.random.seed(983154356)
nr = 10
n_groups = 2
labels = np.arange(n_groups)
x = np.repeat(labels, np.array([40, 60]) * nr)
nobs = x.shape[0]
exog = (x[:, None] == labels).astype(np.float64)
xc = np.random.rand(len(x))
exog = np.column_stack((exog, xc))
# reparameterize to explicit constant
# exog[:, 1] = 1
beta = np.array([0.2, 0.3, 0.5], np.float64)
linpred = exog @ beta
mean = np.exp(linpred)
y = np.random.poisson(mean)
len(y), y.mean(), (y == 0).mean()
res = Poisson(y, exog).fit(disp=0)
print(res.summary())
Poisson Regression Results
==============================================================================
Dep. Variable: y No. Observations: 1000
Model: Poisson Df Residuals: 997
Method: MLE Df Model: 2
Date: Thu, 28 Nov 2024 Pseudo R-squ.: 0.01258
Time: 23:11:02 Log-Likelihood: -1618.3
converged: True LL-Null: -1638.9
Covariance Type: nonrobust LLR p-value: 1.120e-09
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
x1 0.2386 0.061 3.926 0.000 0.120 0.358
x2 0.3229 0.055 5.873 0.000 0.215 0.431
x3 0.5109 0.083 6.186 0.000 0.349 0.673
==============================================================================
[ ]:
推論 - ウォルド¶
fitのcov_typeオプション)。現在利用可能な方法は、パラメータテーブルの統計を除くと以下の通りです:
t_test
wald_test
t_test_pairwise
wald_test_terms
f_testはレガシー(後方互換性)メソッドとして利用可能です。これはwald_testと同じですが、キーワードオプションuse_f=Trueが設定されています。
[3]:
res.t_test("x1=x2")
[3]:
<class 'statsmodels.stats.contrast.ContrastResults'>
Test for Constraints
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
c0 -0.0843 0.049 -1.717 0.086 -0.181 0.012
==============================================================================
[4]:
res.wald_test("x1=x2, x3", scalar=True)
[4]:
<class 'statsmodels.stats.contrast.ContrastResults'>
<Wald test (chi2): statistic=40.77232294429347, p-value=1.4008852592190163e-09, df_denom=2>
推論 - スコア検定¶
これは、statsmodels 0.14 で多くの離散モデルおよびGLMに新しく追加された機能です。
スコア検定またはラグランジュ乗数(LM)検定は、帰無仮説の下で推定されたモデルに基づいています。一般的な例は、変数追加検定で、帰無仮説の下でモデルパラメータを推定しますが、完全モデルでスコアとヘッセ行列を評価し、追加された変数が統計的に有意かどうかを検定します。
注意:
ウォルド検定と同様に、離散モデルおよびGLMに実装されているスコア検定にも、異方分散性または相関ロバストな共分散タイプを使用するオプションがあります。現在、このオプションはウォルド検定のロバスト共分散行列と同じ実装とデフォルトを使用しています。場合によっては、ウォルド検定のcov_typeに含まれる小標本修正がスコア検定には適切でないことがあります。多くの場合、ウォルド検定は過剰に棄却しますが、スコア検定は棄却し過小評価することがあります。ウォルドの小標本修正をスコア検定に使用すると、より保守的なp値が得られる場合があります。
(小標本修正のデフォルトは将来変更される可能性があります。異方分散性および相関ロバストなスコア検定に対する小標本修正については、現在ほとんど一般的な情報がありません。他の統計パッケージでは、いくつかの特別なケースにのみ実装されています。)
仕様検定には変数追加スコア検定(score_test)を使用できます。以下の例では、二次項や多項式項を追加することで、モデルに誤った非線形性があるかどうかを検定します。
この例では、モデルが正しく指定されており、標本サイズが大きいため、これらの仕様検定が帰無仮説を棄却しないことが予想されます。
[5]:
res.score_test(exog_extra=xc**2)
[5]:
(array([0.05300569]), array([0.81791332]), 1)
[6]:
linpred = res.predict(which="linear")
res.score_test(exog_extra=linpred[:,None]**[2, 3])
[6]:
(array([1.3867703]), array([0.49988103]), 2)
予測¶
モデルおよび結果クラスには、予測値のみを返すpredictメソッドがあります。get_predictionメソッドは、予測の推測統計(標準誤差、p値、信頼区間)を追加します。
次の例では、カテゴリカルレベルで分割された説明変数の新しいセットを作成し、連続変数の均等なグリッド上で分割します。
[7]:
n = 11
exc = np.linspace(0, 1, n)
ex1 = np.column_stack((np.ones(n), np.zeros(n), exc))
ex2 = np.column_stack((np.zeros(n), np.ones(n), exc))
m1 = res.get_prediction(ex1)
m2 = res.get_prediction(ex2)
予測結果クラスの利用可能なメソッドと属性は次のとおりです
[8]:
[i for i in dir(m1) if not i.startswith("_")]
[8]:
['conf_int',
'deriv',
'df',
'dist',
'dist_args',
'func',
'linpred',
'linpred_se',
'predicted',
'row_labels',
'se',
'summary_frame',
't_test',
'tvalues',
'var_pred']
[9]:
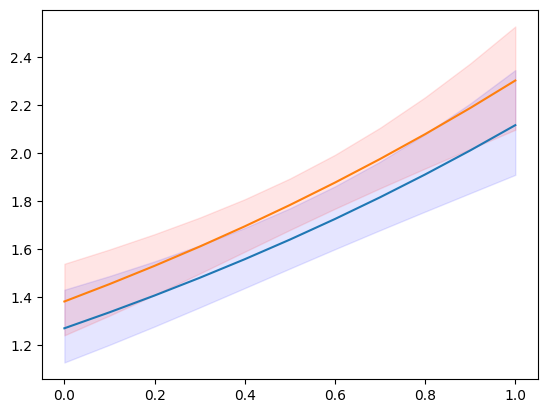
plt.plot(exc, np.column_stack([m1.predicted, m2.predicted]))
ci = m1.conf_int()
plt.fill_between(exc, ci[:, 0], ci[:, 1], color='b', alpha=.1)
ci = m2.conf_int()
plt.fill_between(exc, ci[:, 0], ci[:, 1], color='r', alpha=.1)
# to add observed points:
# y1 = y[x == 0]
# plt.plot(xc[x == 0], y1, ".", color="b", alpha=.3)
# y2 = y[x == 1]
# plt.plot(xc[x == 1], y2, ".", color="r", alpha=.3)
[9]:
<matplotlib.collections.PolyCollection at 0x2aede10e8f0>
[10]:
y.max()
[10]:
np.int32(7)
予測できる利用可能な統計量の 1 つは、 「which」 キーワードで指定され、予測分布の期待頻度または確率です。これは、説明変数の特定のセットに対して、count = 1、2、3、… を観測する予測確率を示します。
[11]:
y_max = 5
f1 = res.get_prediction(ex1, which="prob", y_values=np.arange(y_max + 1))
f2 = res.get_prediction(ex2, which="prob", y_values=np.arange(y_max + 1))
f1.predicted.mean(0), f2.predicted.mean(0)
[11]:
(array([0.19681697, 0.31325239, 0.25570764, 0.14275759, 0.06128168,
0.02154715]),
array([0.17115113, 0.29529781, 0.26128059, 0.15810937, 0.07357482,
0.02804883]))
予測確率の信頼区間を取得することもできます。ただし、平均予測確率の信頼区間が必要な場合は、予測関数内で集計する必要があります。関連するキーワードは 「average」 で、これは exog 配列によって与えられた観測値に対する予測の平均を計算します。
[12]:
f1 = res.get_prediction(ex1, which="prob", y_values=np.arange(y_max + 1), average=True)
f2 = res.get_prediction(ex2, which="prob", y_values=np.arange(y_max + 1), average=True)
f1.predicted, f2.predicted
[12]:
(array([0.19681697, 0.31325239, 0.25570764, 0.14275759, 0.06128168,
0.02154715]),
array([0.17115113, 0.29529781, 0.26128059, 0.15810937, 0.07357482,
0.02804883]))
[13]:
f1.conf_int()
[13]:
array([[0.17256941, 0.22106453],
[0.2982307 , 0.32827408],
[0.24818616, 0.26322912],
[0.12876732, 0.15674787],
[0.05088296, 0.07168041],
[0.01626921, 0.0268251 ]])
[14]:
f2.conf_int()
[14]:
array([[0.15303084, 0.18927142],
[0.28178041, 0.30881522],
[0.25622062, 0.26634055],
[0.14720224, 0.1690165 ],
[0.06442055, 0.0827291 ],
[0.02287077, 0.03322688]])
help(res.get_prediction)help(res.model.predict)分布¶
与えられたパラメータに対して、scipy または scipy 互換の分布クラスのインスタンスを作成できます。これにより、分布内の任意のメソッド(pmf/pdf、cdf、stats)にアクセスできます。
結果クラスの get_distribution メソッドは、提供された説明変数の配列と推定されたパラメータを使用して、ベクトル化された分布を指定します。モデルの get_prediction メソッドは、ユーザー指定のパラメータ params に対して使用できます。
[15]:
distr = res.get_distribution()
distr
[15]:
<scipy.stats._distn_infrastructure.rv_discrete_frozen at 0x2aed9feb550>
[16]:
distr.pmf(0)[:10]
[16]:
array([0.15420516, 0.13109359, 0.17645042, 0.16735421, 0.13445031,
0.14851843, 0.22287053, 0.14979318, 0.25252986, 0.25013583])
条件付き分布の平均は、モデルから予測された平均と同じです。
[17]:
distr.mean()[:10]
[17]:
array([1.86947133, 2.03184379, 1.73471534, 1.78764267, 2.00656061,
1.90704623, 1.50116427, 1.89849971, 1.37622577, 1.3857512 ])
[18]:
res.predict()[:10]
[18]:
array([1.86947133, 2.03184379, 1.73471534, 1.78764267, 2.00656061,
1.90704623, 1.50116427, 1.89849971, 1.37622577, 1.3857512 ])
新しい説明変数セットの分布を取得することもできます。説明変数は、predict メソッドと同じ方法で提供できます。
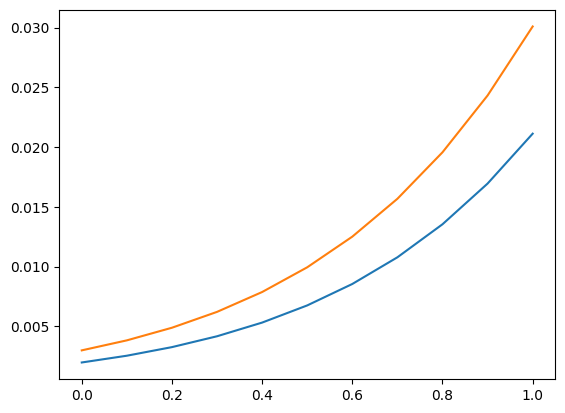
予測セクションの説明変数のグリッドを再度使用します。その使用例として、説明変数の値に応じて、(厳密に) 5 より大きいカウントが観測される確率を計算できます。
[19]:
distr1 = res.get_distribution(ex1)
distr2 = res.get_distribution(ex2)
[20]:
distr1.sf(5), distr2.sf(5)
[20]:
(array([0.00198421, 0.00255027, 0.00326858, 0.00417683, 0.00532093,
0.00675641, 0.00854998, 0.01078116, 0.0135439 , 0.01694825,
0.02112179]),
array([0.00299758, 0.00383456, 0.00489029, 0.00621677, 0.00787663,
0.00994468, 0.01250966, 0.01567579, 0.01956437, 0.02431503,
0.03008666]))
[21]:
plt.plot(exc, np.column_stack([distr1.sf(5), distr2.sf(5)]))
[21]:
[<matplotlib.lines.Line2D at 0x2aede21fa90>,
<matplotlib.lines.Line2D at 0x2aede21fb80>]
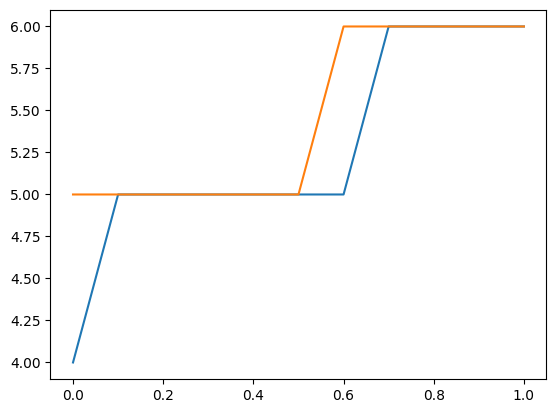
分布を使用して、新しい観測値の信頼度上限を見つけることもできます。次のグラフと表は、特定の説明変数の上限カウントを示しています。このカウント以下を観測する確率は少なくとも 0.99 です。
注意: これはパラメータを固定したものとして扱い、パラメータの不確実性は考慮しません。
[22]:
plt.plot(exc, np.column_stack([distr1.ppf(0.99), distr2.ppf(0.99)]))
[22]:
[<matplotlib.lines.Line2D at 0x2aedf3cd3f0>,
<matplotlib.lines.Line2D at 0x2aedf3cd4e0>]
[23]:
[distr1.ppf(0.99), distr2.ppf(0.99)]
[23]:
[array([4., 5., 5., 5., 5., 5., 5., 6., 6., 6., 6.]),
array([5., 5., 5., 5., 5., 5., 6., 6., 6., 6., 6.])]
診断¶
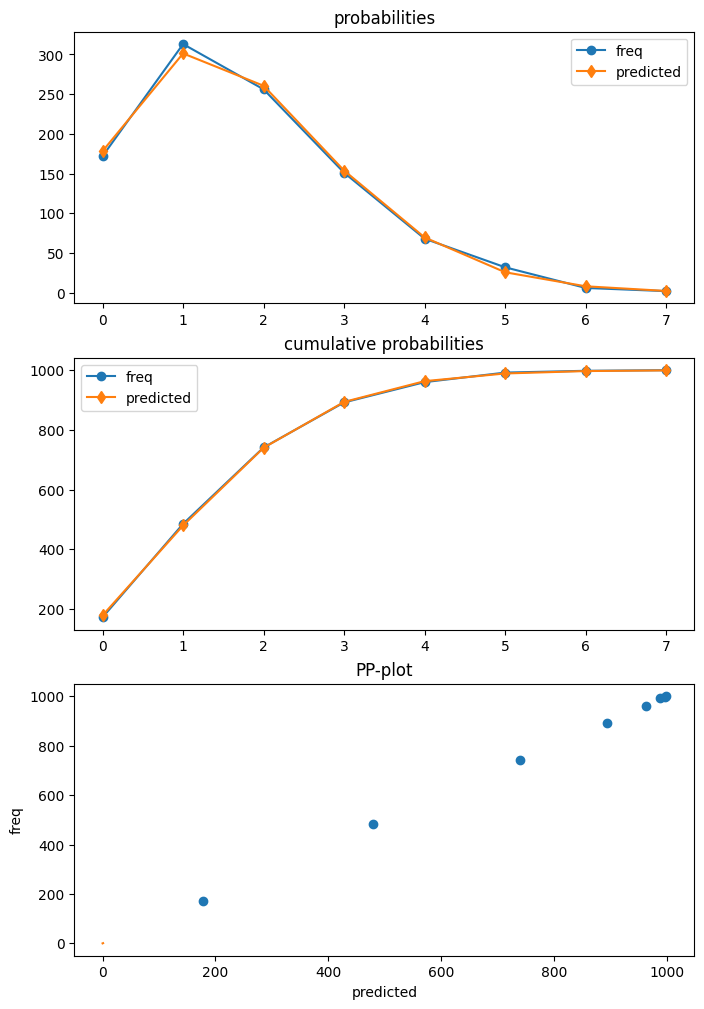
ポアソンは、 get_diagnostic を使用して結果から取得できる診断クラスを持つ最初のモデルです。他のカウント モデルには、現時点では限られた数のメソッドのみを持つ汎用カウント診断クラスがあります。
この例のポアソン モデルは正しく指定されています。また、標本サイズも大きいため、この場合、どの診断検定も正しい指定の帰無仮説を棄却しません。
[24]:
dia = res.get_diagnostic()
[i for i in dir(dia) if not i.startswith("_")]
[24]:
['plot_probs',
'probs_predicted',
'results',
'test_chisquare_prob',
'test_dispersion',
'test_poisson_zeroinflation',
'y_max']
[25]:
dia.plot_probs();
過剰分散の検定
ポアソン分布には、いくつかの分散検定が用意されています。現在、それらすべてが返されます。DispersionResults クラスには summary_frame メソッドがあります。返されるデータフレームには、読みやすい結果の概要が表示されます。
[26]:
td = dia.test_dispersion()
td
[26]:
<class 'statsmodels.discrete._diagnostics_count.DispersionResults'>
statistic = array([-0.42597379, -0.42597379, -0.39884024, -0.48327447, -0.48327447,
-0.47790855, -0.45225818])
pvalue = array([0.67012695, 0.67012695, 0.69001092, 0.62890087, 0.62890087,
0.6327153 , 0.651083 ])
method = ['Dean A', 'Dean B', 'Dean C', 'CT nb2', 'CT nb1', 'CT nb2 HC3', 'CT nb1 HC3']
alternative = ['mu (1 + a mu)', 'mu (1 + a mu)', 'mu (1 + a)', 'mu (1 + a mu)', 'mu (1 + a)', 'mu (1 + a mu)', 'mu (1 + a)']
name = 'Poisson Dispersion Test'
tuple = (array([-0.42597379, -0.42597379, -0.39884024, -0.48327447, -0.48327447,
-0.47790855, -0.45225818]), array([0.67012695, 0.67012695, 0.69001092, 0.62890087, 0.62890087,
0.6327153 , 0.651083 ]))
[27]:
df = td.summary_frame()
df
[27]:
| statistic | pvalue | method | alternative | |
|---|---|---|---|---|
| 0 | -0.425974 | 0.670127 | Dean A | mu (1 + a mu) |
| 1 | -0.425974 | 0.670127 | Dean B | mu (1 + a mu) |
| 2 | -0.398840 | 0.690011 | Dean C | mu (1 + a) |
| 3 | -0.483274 | 0.628901 | CT nb2 | mu (1 + a mu) |
| 4 | -0.483274 | 0.628901 | CT nb1 | mu (1 + a) |
| 5 | -0.477909 | 0.632715 | CT nb2 HC3 | mu (1 + a mu) |
| 6 | -0.452258 | 0.651083 | CT nb1 HC3 | mu (1 + a) |
ゼロインフレーションの検定
[28]:
dia.test_poisson_zeroinflation()
[28]:
<class 'statsmodels.stats.base.HolderTuple'>
statistic = np.float64(-0.6657556201098714)
pvalue = np.float64(0.5055673158225651)
pvalue_smaller = np.float64(0.7472163420887175)
pvalue_larger = np.float64(0.25278365791128254)
chi2 = np.float64(0.44323054570787945)
pvalue_chi2 = np.float64(0.505567315822565)
df_chi2 = 1
distribution = 'normal'
tuple = (np.float64(-0.6657556201098714), np.float64(0.5055673158225651))
ゼロインフレーションのカイ二乗検定
[29]:
dia.test_chisquare_prob(bin_edges=np.arange(3))
[29]:
<class 'statsmodels.stats.base.HolderTuple'>
statistic = np.float64(0.45617094187322405)
pvalue = np.float64(0.49941894681204924)
df = np.int64(1)
diff1 = array([[-0.15420516, 0.71171787],
[-0.13109359, -0.26636169],
[-0.17645042, -0.30609125],
...,
[-0.10477112, -0.23636125],
[-0.10675436, -0.2388335 ],
[-0.21168332, -0.32867305]])
res_aux = <statsmodels.regression.linear_model.RegressionResultsWrapper object at 0x000002AEDE08A470>
distribution = 'chi2'
tuple = (np.float64(0.45617094187322405), np.float64(0.49941894681204924))
予測頻度の適合度検定
これは、パラメータが推定されることを考慮したカイ二乗検定です。最大のビン エッジよりも大きいカウントは最後のビンに追加され、ビン全体の合計が 1 になります。
例えば5つのビンを使う場合
[30]:
dt = dia.test_chisquare_prob(bin_edges=np.arange(6))
dt
[30]:
<class 'statsmodels.stats.base.HolderTuple'>
statistic = np.float64(0.9414641297779136)
pvalue = np.float64(0.9185382008345917)
df = np.int64(4)
diff1 = array([[-0.15420516, 0.71171787, -0.26946759, -0.16792064, -0.07848071],
[-0.13109359, -0.26636169, -0.27060268, 0.81672588, -0.0930961 ],
[-0.17645042, -0.30609125, 0.7345094 , -0.15351687, -0.06657702],
...,
[-0.10477112, -0.23636125, -0.26661279, 0.79950922, -0.11307565],
[-0.10675436, -0.2388335 , 0.73283789, -0.1992339 , -0.11143275],
[-0.21168332, -0.32867305, 0.74484061, -0.13205892, -0.05126078]])
res_aux = <statsmodels.regression.linear_model.RegressionResultsWrapper object at 0x000002AEDF85F7C0>
distribution = 'chi2'
tuple = (np.float64(0.9414641297779136), np.float64(0.9185382008345917))
[31]:
dt.diff1.mean(0)
[31]:
array([-0.00628136, 0.01177308, -0.00449604, -0.00270524, -0.00156519])
[32]:
vars(dia)
[32]:
{'results': <statsmodels.discrete.discrete_model.PoissonResults at 0x2aed9feb2e0>,
'y_max': None,
'_cache': {'probs_predicted': array([[0.15420516, 0.28828213, 0.26946759, ..., 0.02934349, 0.0091428 ,
0.00244174],
[0.13109359, 0.26636169, 0.27060268, ..., 0.03783135, 0.01281123,
0.00371863],
[0.17645042, 0.30609125, 0.2654906 , ..., 0.02309843, 0.0066782 ,
0.00165497],
...,
[0.10477112, 0.23636125, 0.26661279, ..., 0.05101921, 0.01918303,
0.00618235],
[0.10675436, 0.2388335 , 0.26716211, ..., 0.04986002, 0.01859135,
0.00594186],
[0.21168332, 0.32867305, 0.25515939, ..., 0.01591815, 0.00411926,
0.00091369]])}}
外れ値と影響¶
Statsmodelsは、離散モデルやベータ回帰モデルなどの最大尤度推定に基づくモデルに対して、非線形モデル(非線形な期待値を持つモデル)用の一般的な MLEInfluence クラスを提供します。提供される指標は、線形モデルにおけるハット行列の対角成分の代わりに、一般化されたレバレッジなどの一般的な定義に基づいています。
get_influence メソッドは MLEInfluence クラスのインスタンスを返し、これには外れ値や影響度の指標を計算するためのさまざまなメソッドが含まれています。
[33]:
infl = res.get_influence()
[i for i in dir(infl) if not i.startswith("_")]
[33]:
['cooks_distance',
'cov_params',
'd_fittedvalues',
'd_fittedvalues_scaled',
'd_params',
'dfbetas',
'endog',
'exog',
'hat_matrix_diag',
'hat_matrix_exog_diag',
'hessian',
'k_params',
'k_vars',
'model_class',
'nobs',
'params_one',
'plot_index',
'plot_influence',
'resid',
'resid_score',
'resid_score_factor',
'resid_studentized',
'results',
'scale',
'score_obs',
'summary_frame']
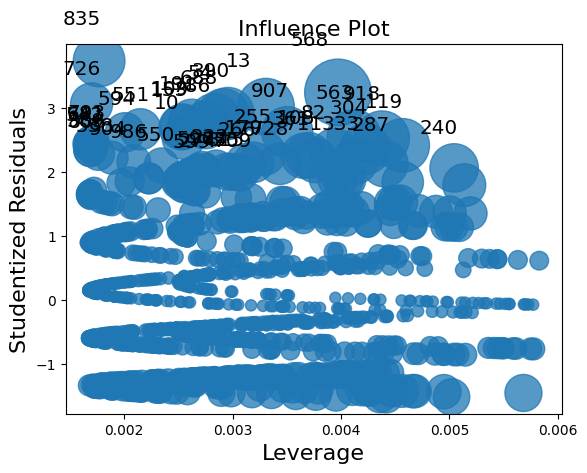
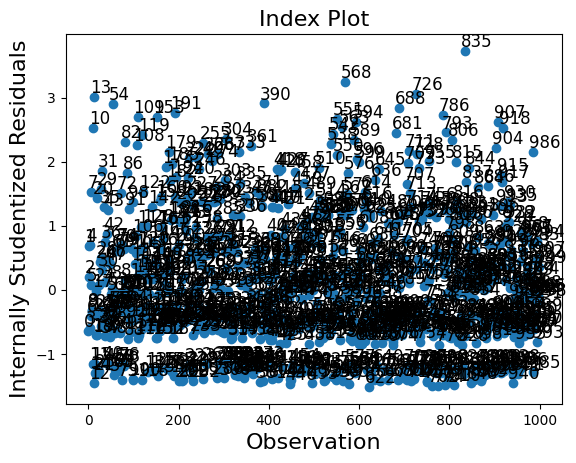
影響クラスには 2 つのプロット方法があります。ただし、この場合は標本サイズが大きいため、プロットが混雑しすぎています。
[34]:
infl.plot_influence();
[35]:
infl.plot_index(y_var="resid_studentized");
summary_frameは、各観測値に対する主な影響度と外れ値の指標を示します。
この例では、観測値が1000件ありますが、これは簡単に表示するには多すぎます。summary_frameを列の1つでソートし、最も大きな外れ値や影響度を持つ観測値をリスト化することができます。以下の例では、クック距離と、一般的なケースでのピアソン残差であるstandard_residでソートしています。
「良い」モデルをシミュレートしたため、大きな影響を持つ観測値や大きな外れ値はありません。
[36]:
df_infl = infl.summary_frame()
df_infl.head()
[36]:
| dfb_x1 | dfb_x2 | dfb_x3 | cooks_d | standard_resid | hat_diag | dffits_internal | |
|---|---|---|---|---|---|---|---|
| 0 | -0.010856 | 0.011384 | -0.013643 | 0.000440 | -0.636944 | 0.003243 | -0.036334 |
| 1 | 0.001990 | -0.023625 | 0.028313 | 0.000737 | 0.680823 | 0.004749 | 0.047031 |
| 2 | 0.005794 | -0.000787 | 0.000943 | 0.000035 | 0.201681 | 0.002607 | 0.010311 |
| 3 | -0.014243 | 0.005539 | -0.006639 | 0.000325 | -0.589923 | 0.002790 | -0.031206 |
| 4 | 0.003602 | -0.022549 | 0.027024 | 0.000738 | 0.702888 | 0.004462 | 0.047057 |
[37]:
df_infl.sort_values("cooks_d", ascending=False)[:10]
[37]:
| dfb_x1 | dfb_x2 | dfb_x3 | cooks_d | standard_resid | hat_diag | dffits_internal | |
|---|---|---|---|---|---|---|---|
| 568 | -0.110520 | -0.038997 | 0.143106 | 0.013922 | 3.236167 | 0.003972 | 0.204365 |
| 13 | 0.048914 | -0.056713 | 0.067969 | 0.010034 | 3.011778 | 0.003307 | 0.173497 |
| 918 | -0.093971 | -0.038431 | 0.121677 | 0.009304 | 2.519367 | 0.004378 | 0.167066 |
| 563 | -0.089917 | -0.033708 | 0.116428 | 0.008935 | 2.545624 | 0.004119 | 0.163720 |
| 119 | 0.163230 | 0.103957 | -0.124589 | 0.008883 | 2.409646 | 0.004569 | 0.163247 |
| 390 | 0.148697 | 0.066972 | -0.080264 | 0.008358 | 2.907190 | 0.002958 | 0.158345 |
| 835 | -0.017672 | 0.066475 | 0.022883 | 0.008209 | 3.727645 | 0.001769 | 0.156931 |
| 54 | 0.145944 | 0.064216 | -0.076961 | 0.008156 | 2.892554 | 0.002916 | 0.156419 |
| 907 | -0.078901 | -0.020908 | 0.102164 | 0.008021 | 2.615676 | 0.003505 | 0.155126 |
| 304 | 0.152905 | 0.093680 | -0.112272 | 0.007821 | 2.351520 | 0.004225 | 0.153179 |
[38]:
df_infl.sort_values("standard_resid", ascending=False)[:10]
[38]:
| dfb_x1 | dfb_x2 | dfb_x3 | cooks_d | standard_resid | hat_diag | dffits_internal | |
|---|---|---|---|---|---|---|---|
| 835 | -0.017672 | 0.066475 | 0.022883 | 0.008209 | 3.727645 | 0.001769 | 0.156931 |
| 568 | -0.110520 | -0.038997 | 0.143106 | 0.013922 | 3.236167 | 0.003972 | 0.204365 |
| 726 | -0.003941 | 0.065200 | 0.005103 | 0.005303 | 3.056406 | 0.001700 | 0.126127 |
| 13 | 0.048914 | -0.056713 | 0.067969 | 0.010034 | 3.011778 | 0.003307 | 0.173497 |
| 390 | 0.148697 | 0.066972 | -0.080264 | 0.008358 | 2.907190 | 0.002958 | 0.158345 |
| 54 | 0.145944 | 0.064216 | -0.076961 | 0.008156 | 2.892554 | 0.002916 | 0.156419 |
| 688 | 0.083205 | 0.148254 | -0.107737 | 0.007606 | 2.833988 | 0.002833 | 0.151057 |
| 191 | 0.122062 | 0.040388 | -0.048403 | 0.006704 | 2.764369 | 0.002625 | 0.141815 |
| 786 | -0.061179 | -0.000408 | 0.079217 | 0.006827 | 2.724900 | 0.002751 | 0.143110 |
| 109 | 0.110999 | 0.029401 | -0.035236 | 0.006212 | 2.704144 | 0.002542 | 0.136518 |