statsmodels 主成分分析 (PCA)¶
主要なアイデア: 主成分分析、世界銀行データ、出生率
このノートブックでは、世界銀行から取得したデータを使用して、192カ国の出生率の時系列データを主成分分析(PCA)で解析します。主な目的は、出生率のトレンドが時間とともに国ごとにどのように異なるかを理解することです。これは、時系列データを使用した主成分分析の少し異例な例です。関数的主成分分析(functional PCA)などの手法がこの設定に対して開発されていますが、出生率データは非常に滑らかであるため、標準的なPCAを使用することに実際の不利はありません。
[1]:
%matplotlib inline
import matplotlib.pyplot as plt
import statsmodels.api as sm
from statsmodels.multivariate.pca import PCA
plt.rc("figure", figsize=(16, 8))
plt.rc("font", size=14)
データは世界銀行のウェブサイトから取得できますが、ここでは少し清掃されたバージョンのデータを使用します。
[2]:
data = sm.datasets.fertility.load_pandas().data
data.head()
[2]:
| Country Name | Country Code | Indicator Name | Indicator Code | 1960 | 1961 | 1962 | 1963 | 1964 | 1965 | ... | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Aruba | ABW | Fertility rate, total (births per woman) | SP.DYN.TFRT.IN | 4.820 | 4.655 | 4.471 | 4.271 | 4.059 | 3.842 | ... | 1.786 | 1.769 | 1.754 | 1.739 | 1.726 | 1.713 | 1.701 | 1.690 | NaN | NaN |
| 1 | Andorra | AND | Fertility rate, total (births per woman) | SP.DYN.TFRT.IN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | 1.240 | 1.180 | 1.250 | 1.190 | 1.220 | NaN | NaN | NaN |
| 2 | Afghanistan | AFG | Fertility rate, total (births per woman) | SP.DYN.TFRT.IN | 7.671 | 7.671 | 7.671 | 7.671 | 7.671 | 7.671 | ... | 7.136 | 6.930 | 6.702 | 6.456 | 6.196 | 5.928 | 5.659 | 5.395 | NaN | NaN |
| 3 | Angola | AGO | Fertility rate, total (births per woman) | SP.DYN.TFRT.IN | 7.316 | 7.354 | 7.385 | 7.410 | 7.425 | 7.430 | ... | 6.704 | 6.657 | 6.598 | 6.523 | 6.434 | 6.331 | 6.218 | 6.099 | NaN | NaN |
| 4 | Albania | ALB | Fertility rate, total (births per woman) | SP.DYN.TFRT.IN | 6.186 | 6.076 | 5.956 | 5.833 | 5.711 | 5.594 | ... | 2.004 | 1.919 | 1.849 | 1.796 | 1.761 | 1.744 | 1.741 | 1.748 | NaN | NaN |
5 rows × 58 columns
ここでは、数値データのみを含む出生率のデータフレームを作成し、インデックスを国名に設定します。また、欠損データがある国をすべて削除します。
[3]:
columns = list(map(str, range(1960, 2012)))
data.set_index("Country Name", inplace=True)
dta = data[columns]
dta = dta.dropna()
dta.head()
[3]:
| 1960 | 1961 | 1962 | 1963 | 1964 | 1965 | 1966 | 1967 | 1968 | 1969 | ... | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Country Name | |||||||||||||||||||||
| Aruba | 4.820 | 4.655 | 4.471 | 4.271 | 4.059 | 3.842 | 3.625 | 3.417 | 3.226 | 3.054 | ... | 1.825 | 1.805 | 1.786 | 1.769 | 1.754 | 1.739 | 1.726 | 1.713 | 1.701 | 1.690 |
| Afghanistan | 7.671 | 7.671 | 7.671 | 7.671 | 7.671 | 7.671 | 7.671 | 7.671 | 7.671 | 7.671 | ... | 7.484 | 7.321 | 7.136 | 6.930 | 6.702 | 6.456 | 6.196 | 5.928 | 5.659 | 5.395 |
| Angola | 7.316 | 7.354 | 7.385 | 7.410 | 7.425 | 7.430 | 7.422 | 7.403 | 7.375 | 7.339 | ... | 6.778 | 6.743 | 6.704 | 6.657 | 6.598 | 6.523 | 6.434 | 6.331 | 6.218 | 6.099 |
| Albania | 6.186 | 6.076 | 5.956 | 5.833 | 5.711 | 5.594 | 5.483 | 5.376 | 5.268 | 5.160 | ... | 2.195 | 2.097 | 2.004 | 1.919 | 1.849 | 1.796 | 1.761 | 1.744 | 1.741 | 1.748 |
| United Arab Emirates | 6.928 | 6.910 | 6.893 | 6.877 | 6.861 | 6.841 | 6.816 | 6.783 | 6.738 | 6.679 | ... | 2.428 | 2.329 | 2.236 | 2.149 | 2.071 | 2.004 | 1.948 | 1.903 | 1.868 | 1.841 |
5 rows × 52 columns
PCAを用いて矩形行列を分析する方法は2通りあります。1つは行を「オブジェクト」とし、列を「変数」として扱う方法、もう1つはその逆です。ここでは、出生率の指標を「変数」として扱い、国々を「オブジェクト」として測定します。したがって、目標は、異なる国々における時間的な変動のほとんどを捉える出生率の「プロファイル」または「基底関数」に、年間の出生率値を縮約することです。
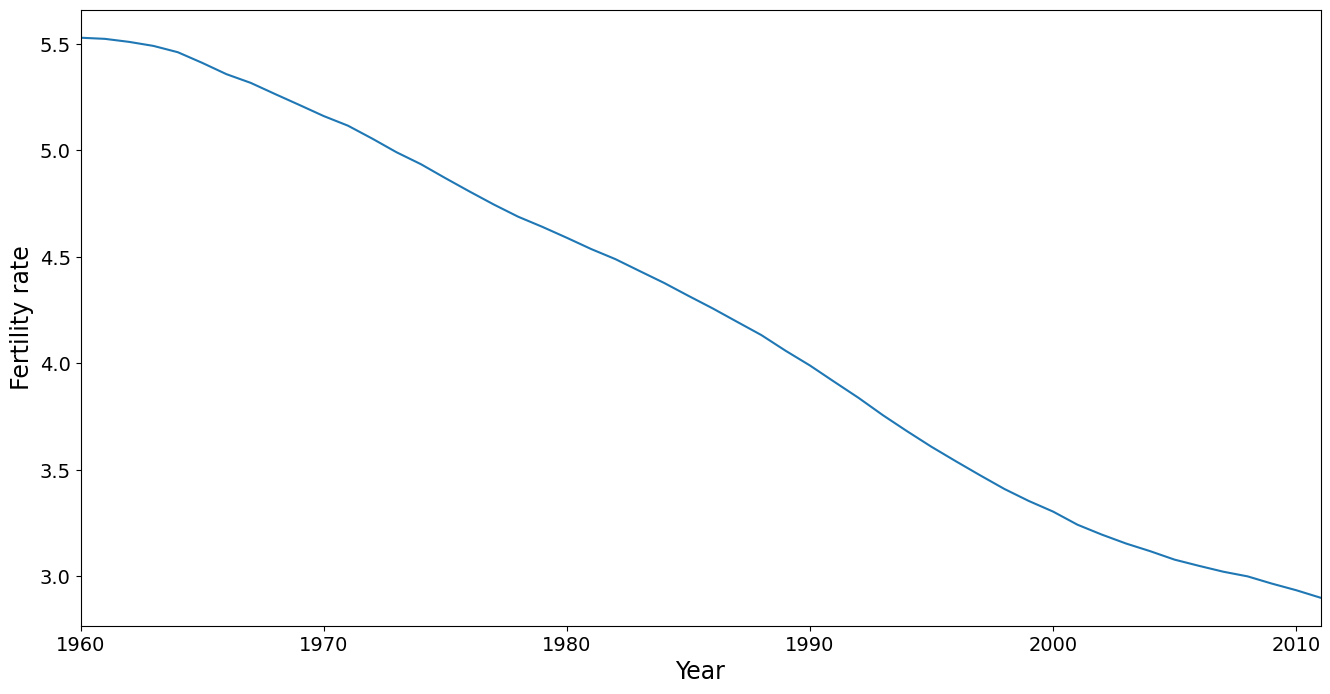
PCAでは平均トレンドが除去されますが、それを確認する価値はあります。このトレンドは、このデータセットでカバーされている期間にわたって、出生率が着実に低下していることを示しています。注意すべきは、平均が国を分析単位として計算され、人口規模は無視されていることです。これは、下で行う主成分分析(PC分析)にも当てはまります。より高度な分析では、たとえば1980年の人口を基に各国に重みを付けることが考えられます。
[4]:
ax = dta.mean().plot(grid=False)
ax.set_xlabel("Year", size=17)
ax.set_ylabel("Fertility rate", size=17)
ax.set_xlim(0, 51)
[4]:
(0.0, 51.0)
次に PCA を実行します:
[5]:
pca_model = PCA(dta.T, standardize=False, demean=True)
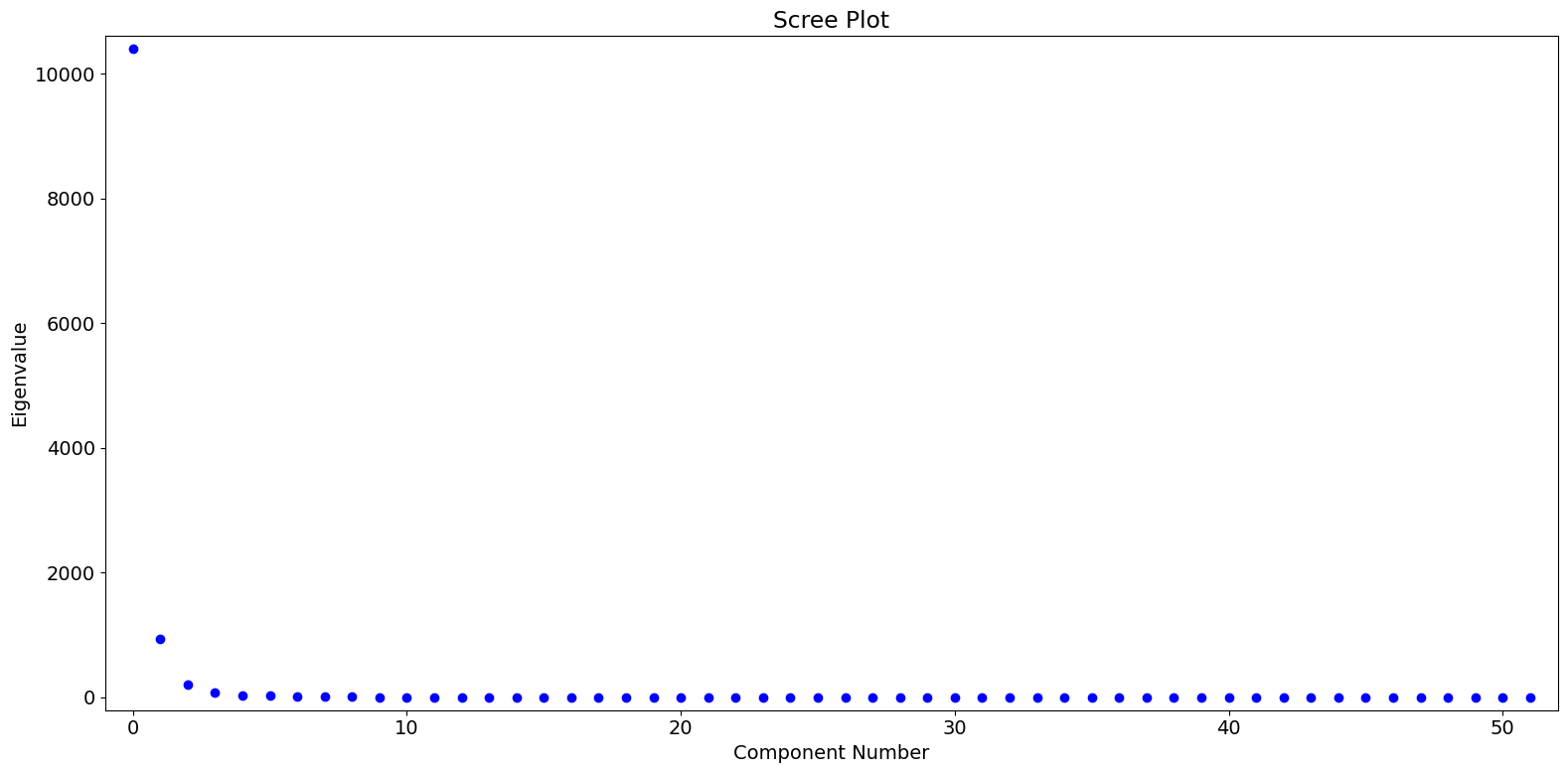
固有値に基づいて、最初の主成分(PC)が支配的であり、第二および第三の主成分に少量の意味のある変動が捉えられている可能性があることがわかります。
[6]:
fig = pca_model.plot_scree(log_scale=False)
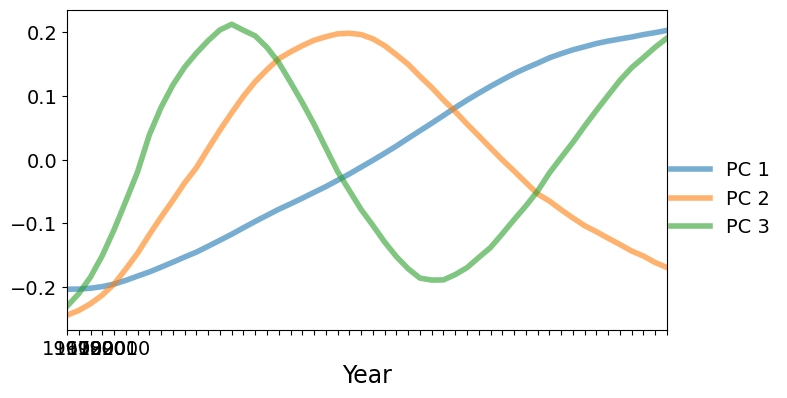
次に、主成分分析(PC)の因子をプロットします。主要な因子は単調に増加しています。最初の因子で正のスコアを持つ国々は、上記の平均と比較して速く増加する(または遅く減少する)ことになります。最初の因子で負のスコアを持つ国々は、平均よりも速く減少します。2番目の因子はU字型で、1985年頃に正のピークがあります。2番目の因子で大きな正のスコアを持つ国々は、データ範囲の最初と最後では平均より低い出生率を持ちますが、範囲の中間では平均より高い出生率を示します。
[7]:
fig, ax = plt.subplots(figsize=(8, 4))
lines = ax.plot(pca_model.factors.iloc[:, :3], lw=4, alpha=0.6)
ax.set_xticklabels(dta.columns.values[::10])
ax.set_xlim(0, 51)
ax.set_xlabel("Year", size=17)
fig.subplots_adjust(0.1, 0.1, 0.85, 0.9)
legend = fig.legend(lines, ["PC 1", "PC 2", "PC 3"], loc="center right")
legend.draw_frame(False)
C:\Users\user\AppData\Local\Temp\ipykernel_20312\427128218.py:3: UserWarning: set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
ax.set_xticklabels(dta.columns.values[::10])
何が起こっているのかをより良く理解するために、似たようなPCスコアを持つ国々の出生率の軌跡をプロットします。以下の便利な関数はそのようなプロットを作成します。
[8]:
idx = pca_model.loadings.iloc[:, 0].argsort()
まず、主成分1(PC 1)のスコアが最も高い5つの国をプロットします。これらの国々は、世界平均(減少している)よりも高い出生率の増加を示しています。
[9]:
def make_plot(labels):
fig, ax = plt.subplots(figsize=(9, 5))
ax = dta.loc[labels].T.plot(legend=False, grid=False, ax=ax)
dta.mean().plot(ax=ax, grid=False, label="Mean")
ax.set_xlim(0, 51)
fig.subplots_adjust(0.1, 0.1, 0.75, 0.9)
ax.set_xlabel("Year", size=17)
ax.set_ylabel("Fertility", size=17)
legend = ax.legend(
*ax.get_legend_handles_labels(), loc="center left", bbox_to_anchor=(1, 0.5)
)
legend.draw_frame(False)
[10]:
labels = dta.index[idx[-5:]]
make_plot(labels)
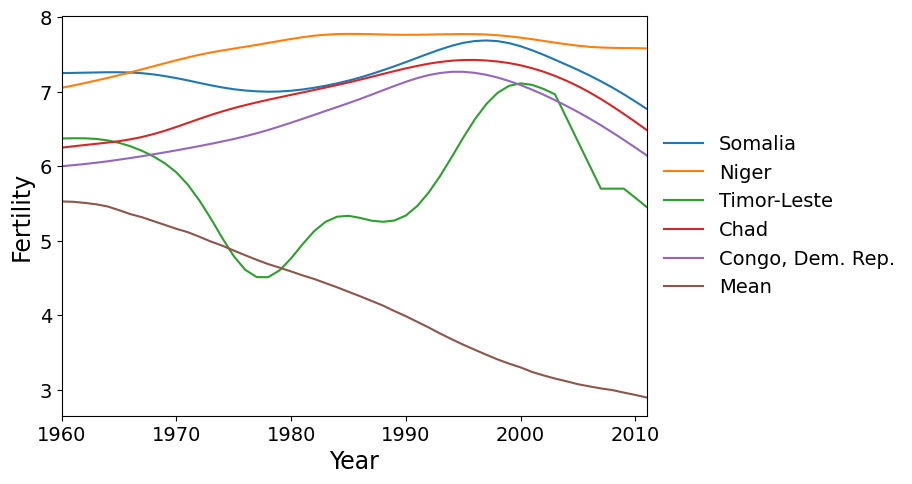
こちらは、要因2で最も高いスコアを持つ5つの国です。これらの国々は、1980年頃にピーク出生率に達し、その後、世界の多くの国々より遅れて急激な出生率の減少を経験しました。
[11]:
idx = pca_model.loadings.iloc[:, 1].argsort()
make_plot(dta.index[idx[-5:]])

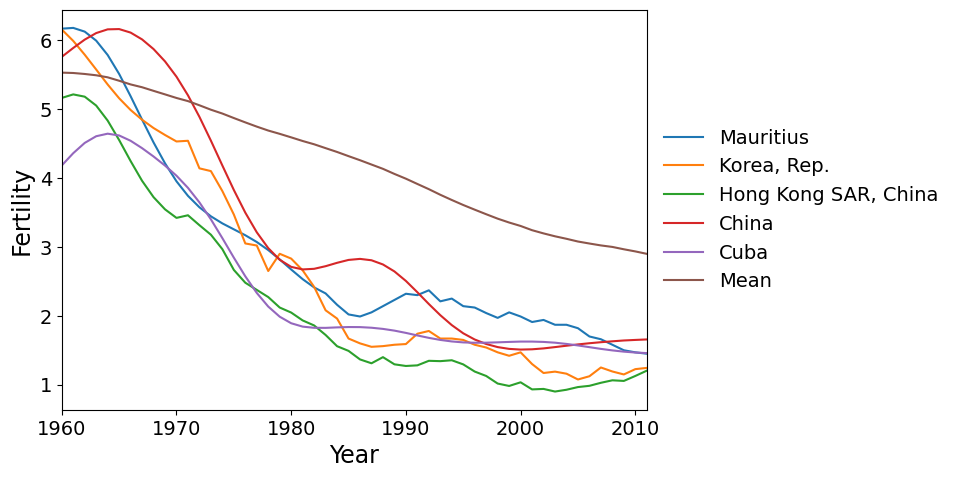
最後に、PC 2で最も負のスコアを持つ国々があります。これらの国々は、1960年代と1970年代において、世界平均よりもはるかに速く出生率が低下し、その後横ばいになった国々です。
[12]:
make_plot(dta.index[idx[:5]])
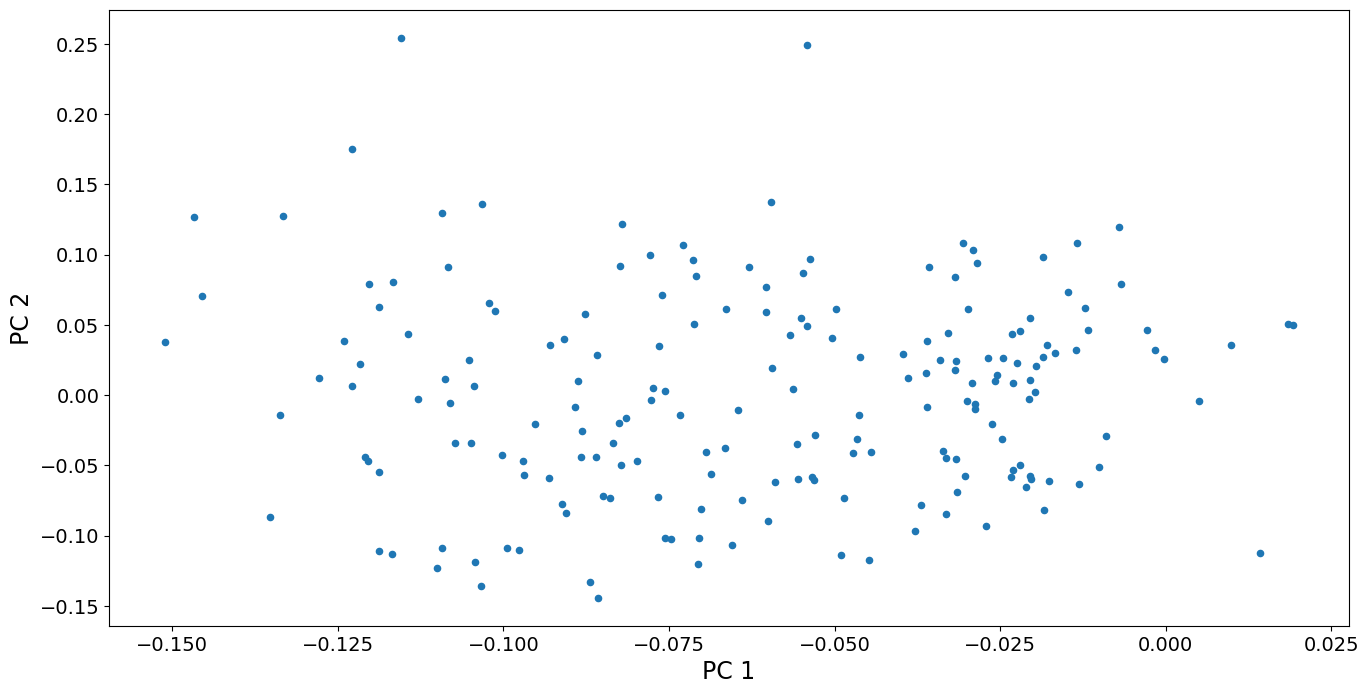
最初の2つの主成分スコアの散布図も見ることができます。国々の間の変動はかなり連続的であることがわかりますが、PC 2のスコアが最も高い2国、オマーンとイエメンが他の点から多少離れている点が見受けられます。これらの国々は、1980年頃に出生率が急激に上昇するという独特の特徴を持っています。他の国々にはそのような急激な上昇は見られません。対照的に、PC 1のスコアが高い国々(出生率が継続的に増加している国々)は、変動の連続体の一部を形成しています。
[13]:
fig, ax = plt.subplots()
pca_model.loadings.plot.scatter(x="comp_00", y="comp_01", ax=ax)
ax.set_xlabel("PC 1", size=17)
ax.set_ylabel("PC 2", size=17)
dta.index[pca_model.loadings.iloc[:, 1] > 0.2].values
[13]:
array(['Oman', 'Yemen, Rep.'], dtype=object)