シータモデル (Theta Model)¶
Assimakopoulos & Nikolopoulos (2000) によるシータモデルは、シンプルな予測手法であり、2つの \(\theta\) 線をフィッティングし、これらの線を単純指数平滑法(SES)で予測した後、2つの線から得られた予測を組み合わせて最終的な予測を生成します。このモデルは以下の手順で実装されます:
季節性の検定
季節性が検出された場合は季節性を除去
SESモデルをデータにフィットさせて \(\alpha\) を推定し、OLSにより \(b_0\) を推定
時系列を予測
季節性を除去した場合は再び季節性を付加
季節性検定は、自己相関関数(ACF)を季節ラグ \(m\) で調べます。このラグが有意にゼロと異なる場合、statsmodels.tsa.seasonal_decompose を使用してデータの季節性を除去します。方法は、乗法的(デフォルト)または加法的のいずれかを選択可能です。
モデルのパラメータは \(b_0\) と \(\alpha\) で、\(b_0\) は以下のOLS回帰によって推定されます:
また、\(\alpha\) は以下のSES平滑化パラメータです:
予測値は次のように計算されます:
最終的に、\(\theta\) はトレンドの抑制度合いを決定する役割を果たします。\(\theta\) が非常に大きい場合、このモデルの予測はドリフト付きの差分移動平均モデル(Integrated Moving Average)と同一になります:
必要に応じて、予測値は季節性を再付加されます。
このモジュールは以下の研究に基づいています:
Assimakopoulos, V., & Nikolopoulos, K. (2000). The theta model: a decomposition approach to forecasting. International journal of forecasting, 16(4), 521-530.
Hyndman, R. J., & Billah, B. (2003). Unmasking the Theta method. International Journal of Forecasting, 19(2), 287-290.
Fioruci, J. A., Pellegrini, T. R., Louzada, F., & Petropoulos, F. (2015). The optimized theta method. arXiv preprint arXiv:1503.03529.
インポート¶
まず、標準的なインポートと、デフォルトのmatplotlibスタイルにいくつか調整を加えます。
[1]:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pandas_datareader as pdr
import seaborn as sns
plt.rc("figure", figsize=(16, 8))
plt.rc("font", size=15)
plt.rc("lines", linewidth=3)
sns.set_style("darkgrid")
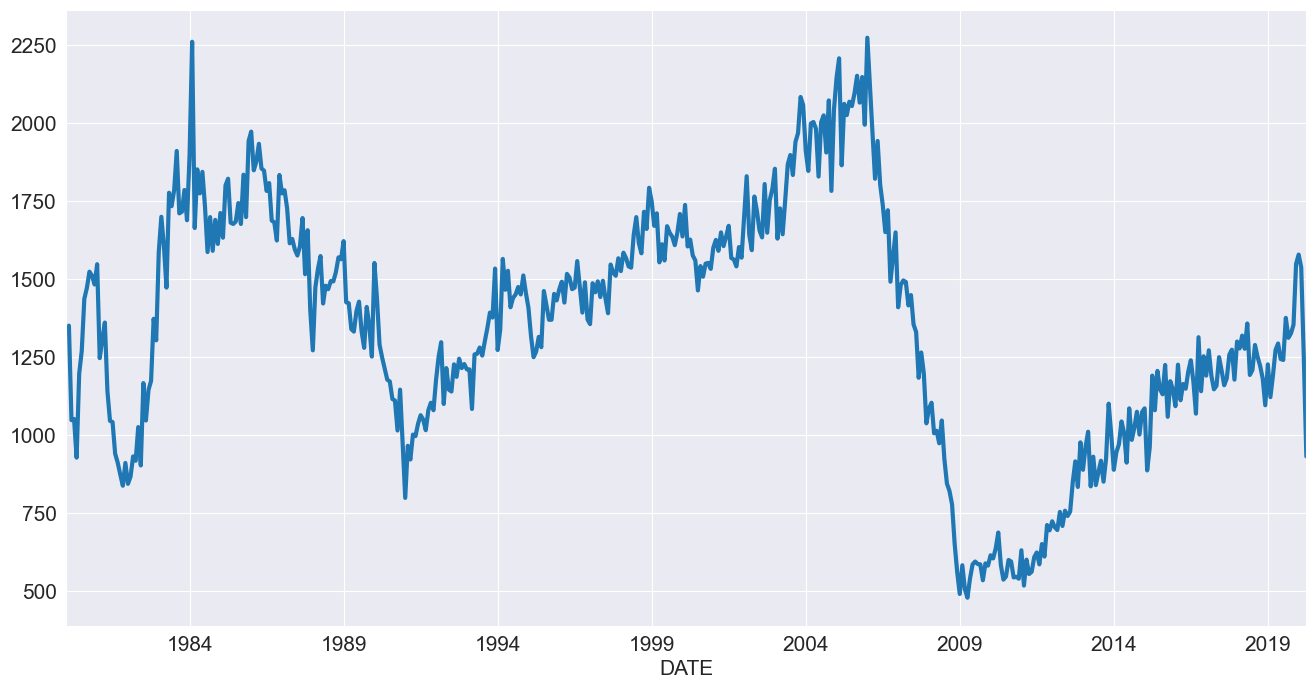
データの読み込み¶
まず、アメリカの住宅着工件数のデータを見てみます。この時系列データは明らかに季節性がある一方で、同じ期間内では明確なトレンドが見られません。
[2]:
reader = pdr.fred.FredReader(["HOUST"], start="1980-01-01", end="2020-04-01")
data = reader.read()
housing = data.HOUST
housing.index.freq = housing.index.inferred_freq
ax = housing.plot()
オプションを指定せずにモデルを定義し、フィットさせます。サマリーでは、データが乗法的手法を使用して季節性を除去されたことが示されています。ドリフトは控えめで負の値を持ち、平滑化パラメータは比較的低い値となっています。
[3]:
from statsmodels.tsa.forecasting.theta import ThetaModel
tm = ThetaModel(housing)
res = tm.fit()
print(res.summary())
ThetaModel Results
==============================================================================
Dep. Variable: HOUST No. Observations: 484
Method: OLS/SES Deseasonalized: True
Date: Wed, 28 Aug 2024 Deseas. Method: Multiplicative
Time: 15:07:09 Period: 12
Sample: 01-01-1980
- 04-01-2020
Parameter Estimates
=========================
Parameters
-------------------------
b0 -0.9194460961668147
alpha 0.616996789006705
-------------------------
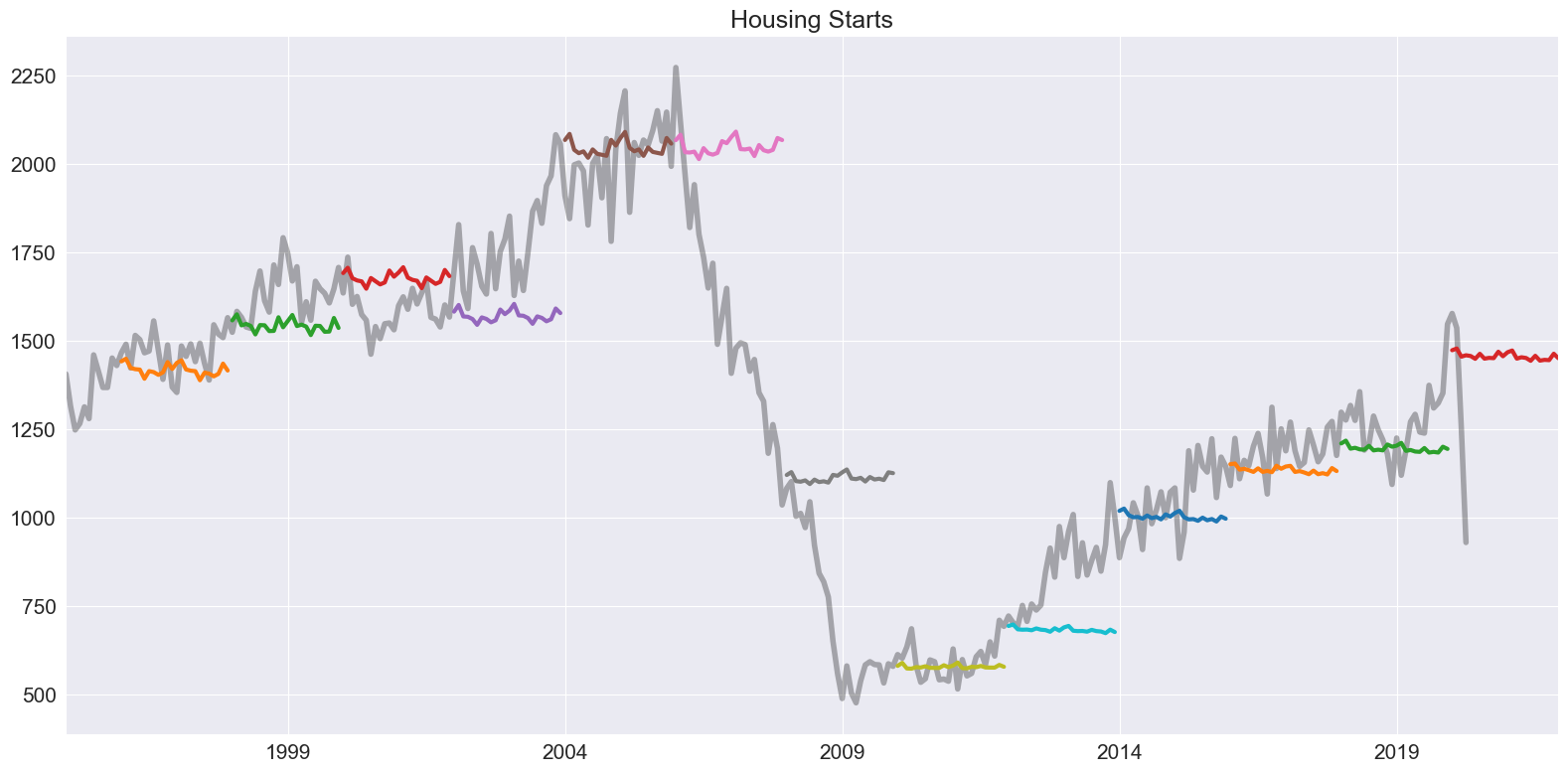
このモデルは、何よりもまず予測手法として設計されています。予測は、フィット済みモデルの forecast メソッドを使用して生成されます。以下では、2年先までの予測を2年ごとに行い、ヘッジホッグプロットを作成します。
注意: デフォルトの \(\theta\) 値は2です。
[4]:
forecasts = {"housing": housing}
for year in range(1995, 2020, 2):
sub = housing[: str(year)]
res = ThetaModel(sub).fit()
fcast = res.forecast(24)
forecasts[str(year)] = fcast
forecasts = pd.DataFrame(forecasts)
ax = forecasts["1995":].plot(legend=False)
children = ax.get_children()
children[0].set_linewidth(4)
children[0].set_alpha(0.3)
children[0].set_color("#000000")
ax.set_title("Housing Starts")
plt.tight_layout(pad=1.0)
データの対数をフィットさせる方法も選択可能です。この場合、必要に応じて季節性の除去には加法的な方法を強制的に使用する方が適しています。また、モデルパラメータは最尤推定(MLE)を使用してフィットさせます。この方法では、以下のような差分移動平均モデル(IMA)をフィットします:
ここで、\(\hat{\alpha} = \min(\hat{\gamma}+1, 0.9998)\) とし、statsmodels.tsa.SARIMAX を用いて推定します。パラメータは類似していますが、ドリフトはゼロに近い値になります。
[5]:
tm = ThetaModel(np.log(housing), method="additive")
res = tm.fit(use_mle=True)
print(res.summary())
ThetaModel Results
==============================================================================
Dep. Variable: HOUST No. Observations: 484
Method: MLE Deseasonalized: True
Date: Wed, 28 Aug 2024 Deseas. Method: Additive
Time: 15:07:10 Period: 12
Sample: 01-01-1980
- 04-01-2020
Parameter Estimates
=============================
Parameters
-----------------------------
b0 -0.00044644118691643226
alpha 0.670610385005854
-----------------------------
\[\hat{b}_0 \left[h - 1 + \frac{1}{\hat{\alpha}} - \frac{(1-\hat{\alpha})^T}{\hat{\alpha}} \right],\]
単純指数平滑法(SES)からの予測(予測期間に関わらず一定)、および季節成分に依存します。これら3つの成分は、forecast_components を使用して取得できます。この機能により、上記の重み表現を用いて複数の \(\theta\) の選択肢を基に予測を構築することが可能です。
[6]:
res.forecast_components(12)
[6]:
| trend | ses | seasonal | |
|---|---|---|---|
| 2020-05-01 | -0.000666 | 6.95726 | -0.001252 |
| 2020-06-01 | -0.001112 | 6.95726 | -0.006891 |
| 2020-07-01 | -0.001559 | 6.95726 | 0.002992 |
| 2020-08-01 | -0.002005 | 6.95726 | -0.003817 |
| 2020-09-01 | -0.002451 | 6.95726 | -0.003902 |
| 2020-10-01 | -0.002898 | 6.95726 | -0.003981 |
| 2020-11-01 | -0.003344 | 6.95726 | 0.008536 |
| 2020-12-01 | -0.003791 | 6.95726 | -0.000714 |
| 2021-01-01 | -0.004237 | 6.95726 | 0.005239 |
| 2021-02-01 | -0.004684 | 6.95726 | 0.009943 |
| 2021-03-01 | -0.005130 | 6.95726 | -0.004535 |
| 2021-04-01 | -0.005577 | 6.95726 | -0.001619 |
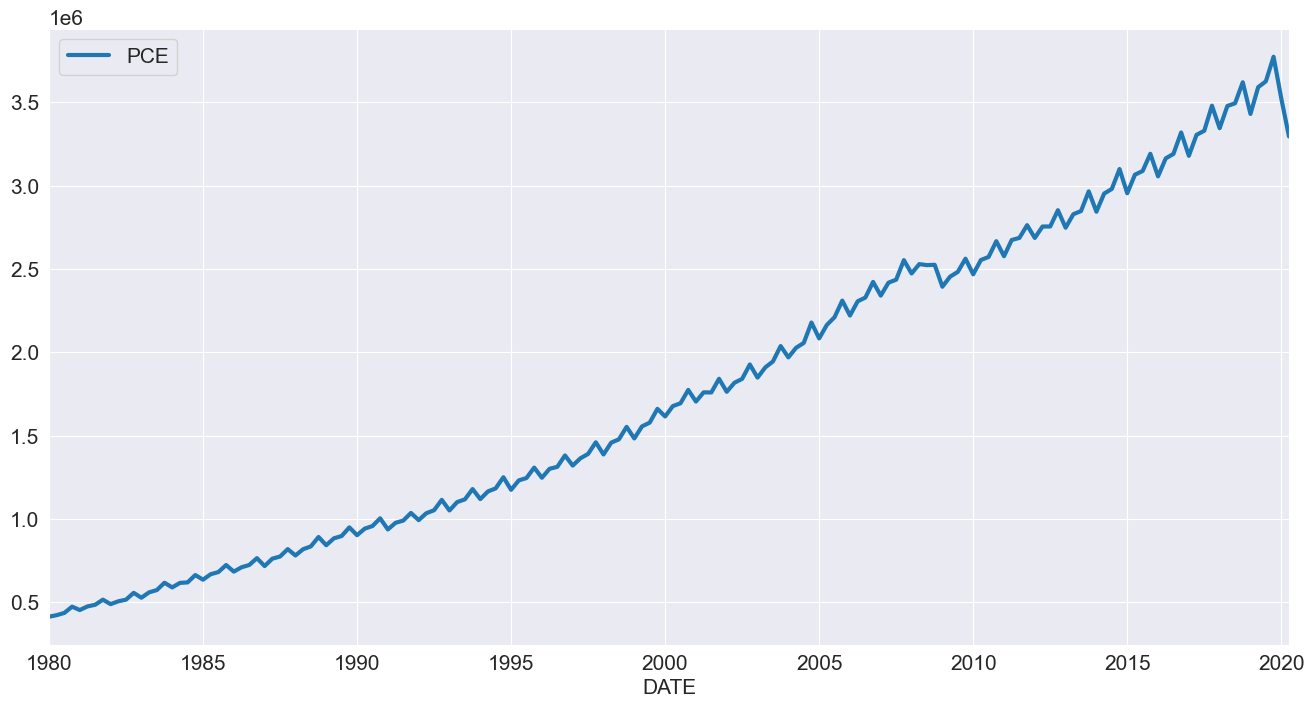
個人消費支出 (Personal Consumption Expenditure)¶
次に、個人消費支出について見ていきます。この系列には明確な季節性の要素とドリフトが見られます。
[7]:
reader = pdr.fred.FredReader(["NA000349Q"], start="1980-01-01", end="2020-04-01")
pce = reader.read()
pce.columns = ["PCE"]
pce.index.freq = "QS-OCT"
_ = pce.plot()
この時系列は常に正の値を取るため、\(\ln\) をモデル化します。
[8]:
mod = ThetaModel(np.log(pce))
res = mod.fit()
print(res.summary())
ThetaModel Results
==============================================================================
Dep. Variable: PCE No. Observations: 162
Method: OLS/SES Deseasonalized: True
Date: Wed, 28 Aug 2024 Deseas. Method: Multiplicative
Time: 15:07:10 Period: 4
Sample: 01-01-1980
- 04-01-2020
Parameter Estimates
==========================
Parameters
--------------------------
b0 0.013033717713127177
alpha 0.9998852832562729
--------------------------
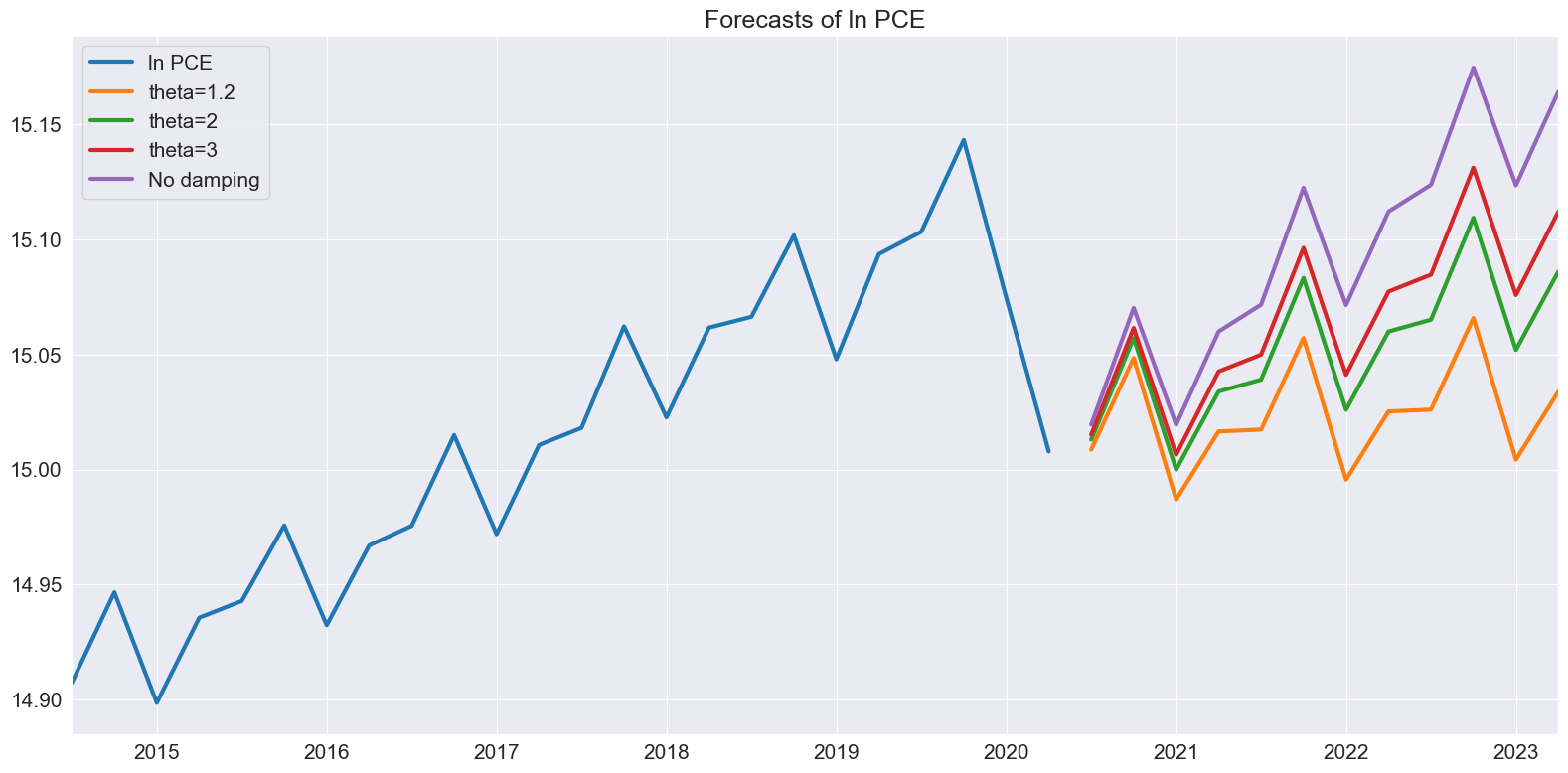
次に、\(\theta\) の変化に伴う予測の違いを調べます。\(\theta\) が1に近い場合、ドリフトはほとんど見られません。\(\theta\) が増加すると、ドリフトがより顕著になります。
[9]:
forecasts = pd.DataFrame(
{
"ln PCE": np.log(pce.PCE),
"theta=1.2": res.forecast(12, theta=1.2),
"theta=2": res.forecast(12),
"theta=3": res.forecast(12, theta=3),
"No damping": res.forecast(12, theta=np.inf),
}
)
_ = forecasts.tail(36).plot()
plt.title("Forecasts of ln PCE")
plt.tight_layout(pad=1.0)
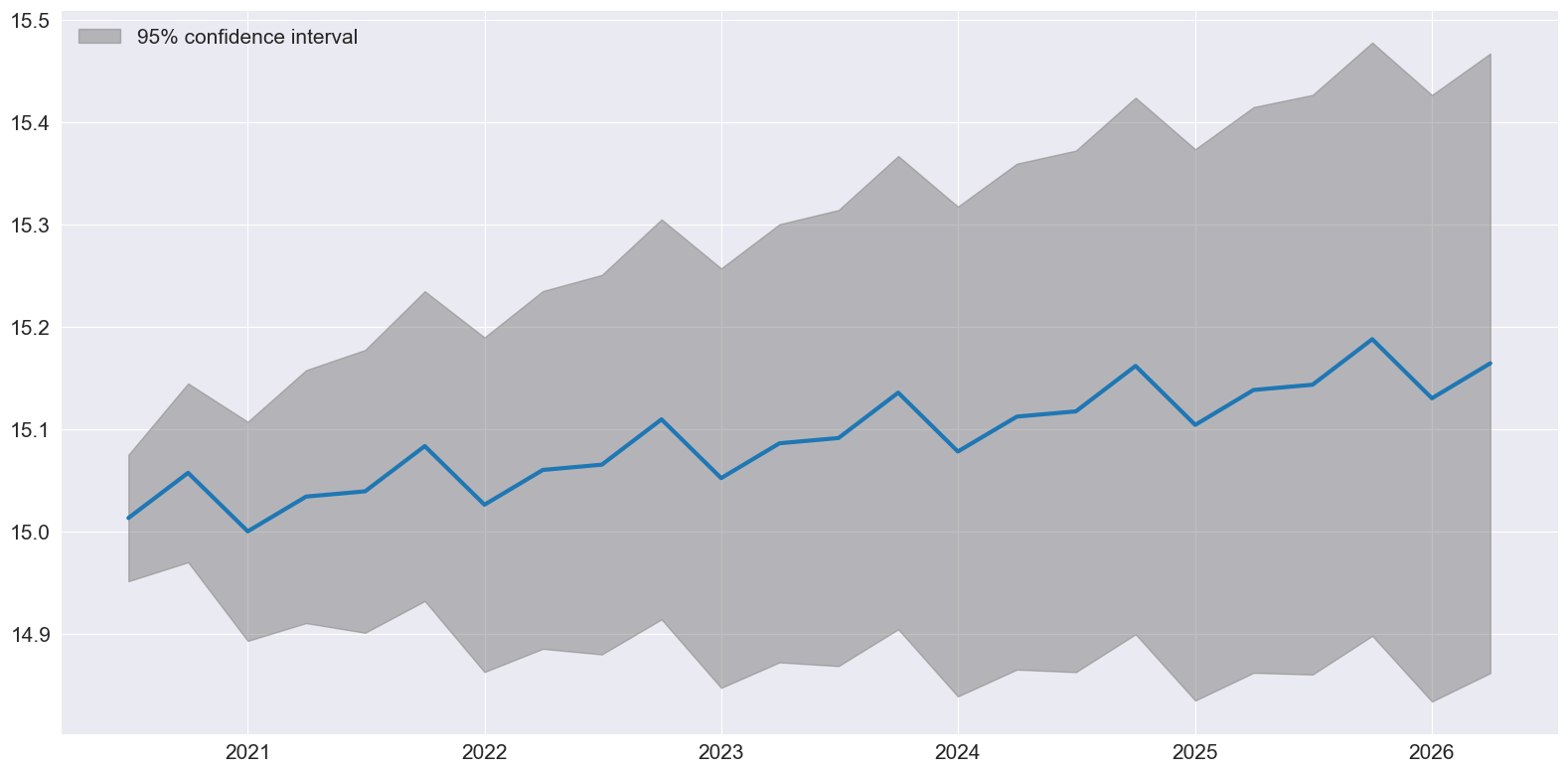
最後に、plot_predict を使用して、IMA(統合移動平均モデル)が真であると仮定して構築された予測値と予測区間を視覚化することができます。
[10]:
ax = res.plot_predict(24, theta=2)
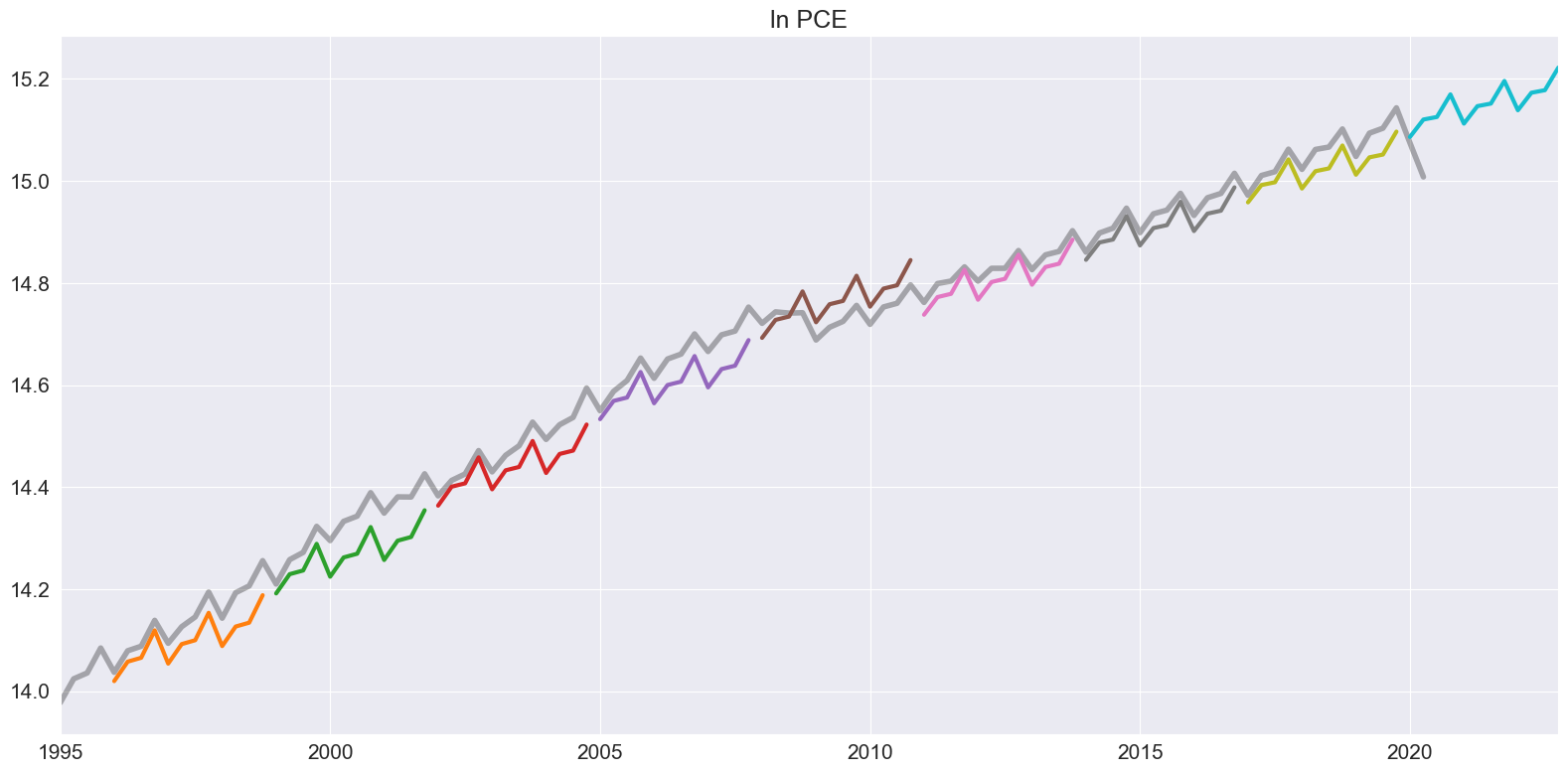
2年の非重複サンプルを使用してハリネズミプロットを作成することで結論とします。
[11]:
ln_pce = np.log(pce.PCE)
forecasts = {"ln PCE": ln_pce}
for year in range(1995, 2020, 3):
sub = ln_pce[: str(year)]
res = ThetaModel(sub).fit()
fcast = res.forecast(12)
forecasts[str(year)] = fcast
forecasts = pd.DataFrame(forecasts)
ax = forecasts["1995":].plot(legend=False)
children = ax.get_children()
children[0].set_linewidth(4)
children[0].set_alpha(0.3)
children[0].set_color("#000000")
ax.set_title("ln PCE")
plt.tight_layout(pad=1.0)