コピュラ - 多変量の結合分布¶
[1]:
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from scipy import stats
sns.set_style("darkgrid")
sns.mpl.rc("figure", figsize=(8, 8))
[2]:
%%javascript
IPython.OutputArea.prototype._should_scroll = function(lines) {
return false;
}
システムをモデル化する際、複数のパラメータが関与する場合がよくあります。これらの各パラメータは、それぞれ特定の確率密度関数(PDF)で記述されることができます。新しいパラメータ値のセットを生成したい場合、これらの分布(マージナルとも呼ばれる)からサンプリングできる必要があります。主に以下の2つの場合があります:(i) PDFが独立している場合;(ii) 依存関係がある場合。依存関係をモデル化する1つの方法として、コピュラを使用する方法があります。
コピュラからのサンプリング¶
2変量の例を使用し、まず事前分布があり、2つの変数間の依存関係をどのようにモデル化するかを知っていると仮定します。
この場合、グンベル・コピュラ(Gumbel copulas)を使用し、そのハイパーパラメータをtheta=2に固定します。この2次元の確率密度関数(PDF)を視覚化することができます。
[3]:
from statsmodels.distributions.copula.api import (
CopulaDistribution, GumbelCopula, IndependenceCopula)
copula = GumbelCopula(theta=2)
_ = copula.plot_pdf() # returns a matplotlib figure
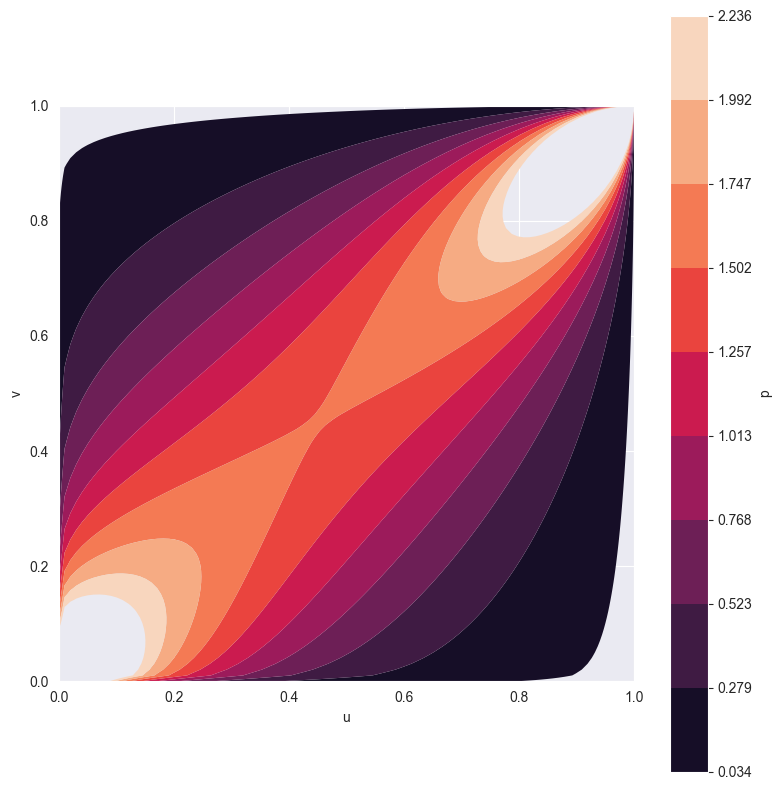
そして、PDFをサンプリングすることができます。
[4]:
sample = copula.rvs(10000)
h = sns.jointplot(x=sample[:, 0], y=sample[:, 1], kind="hex")
_ = h.set_axis_labels("X1", "X2", fontsize=16)
C:\Users\user\projects\statsmodels-main\statsmodels\tools\rng_qrng.py:54: FutureWarning: Passing `None` as the seed currently return the NumPy singleton RandomState
(np.random.mtrand._rand). After release 0.13 this will change to using the
default generator provided by NumPy (np.random.default_rng()). If you need
reproducible draws, you should pass a seeded np.random.Generator, e.g.,
import numpy as np
seed = 32839283923801
rng = np.random.default_rng(seed)"
warnings.warn(_future_warn, FutureWarning)
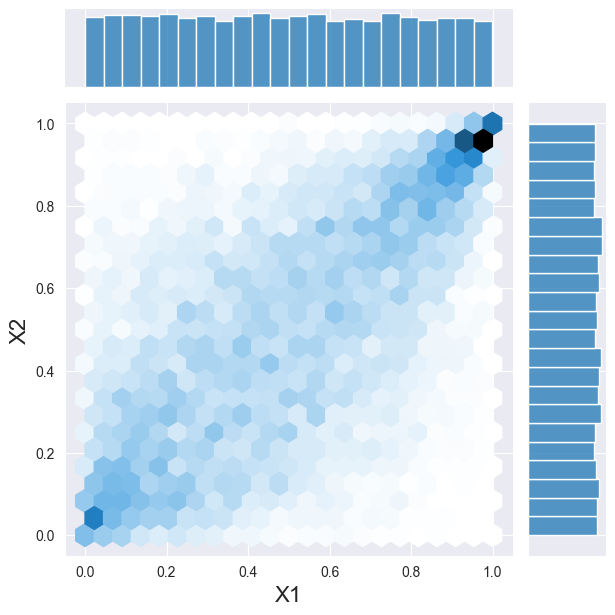
2つの変数に戻ってみましょう。この場合、それらがガンマ分布と正規分布に従うと仮定します。もしこれらの変数が互いに独立している場合、それぞれの確率密度関数(PDF)から個別にサンプリングすることができます。ここでは、同じ操作を行うための便利なクラスを使用します。
再現性¶
コピュラから再現可能なランダム値を生成するには、 seed 引数を明示的に設定する必要があります。 seed は、初期化された NumPy の Generator または RandomState 、または np.random.default_rng で受け入れ可能な任意の引数(例: 整数や整数のシーケンス)を受け付けます。この例では整数を使用します。
np.random の分布で直接使用されるシングルトンの RandomState は使用されず、 np.random.seed を設定しても生成される値には影響しません。
[5]:
marginals = [stats.gamma(2), stats.norm]
joint_dist = CopulaDistribution(copula=IndependenceCopula(), marginals=marginals)
sample = joint_dist.rvs(512, random_state=20210801)
h = sns.jointplot(x=sample[:, 0], y=sample[:, 1], kind="scatter")
_ = h.set_axis_labels("X1", "X2", fontsize=16)
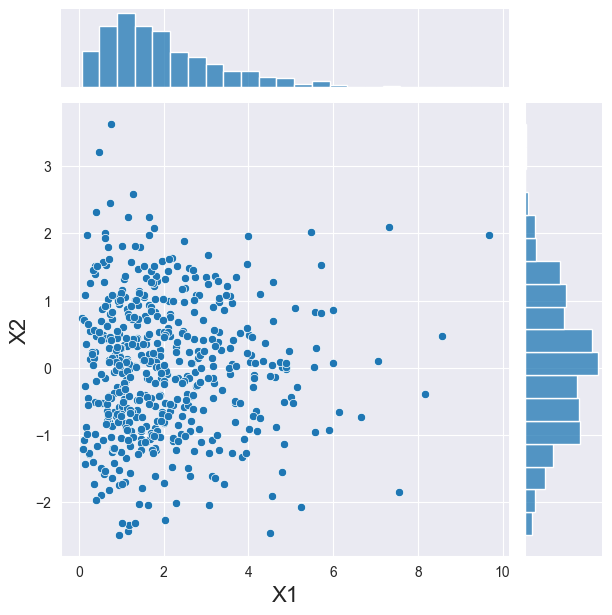
さて、上記では、変数間の依存関係をコピュラを使用して表現しました。このコピュラを利用して、同じ便利なクラスに属する新しい観測値のセットをサンプリングすることができます。
[6]:
joint_dist = CopulaDistribution(copula, marginals)
# Use an initialized Generator object
rng = np.random.default_rng([2, 0, 2, 1, 0, 8, 0, 1])
sample = joint_dist.rvs(512, random_state=rng)
h = sns.jointplot(x=sample[:, 0], y=sample[:, 1], kind="scatter")
_ = h.set_axis_labels("X1", "X2", fontsize=16)
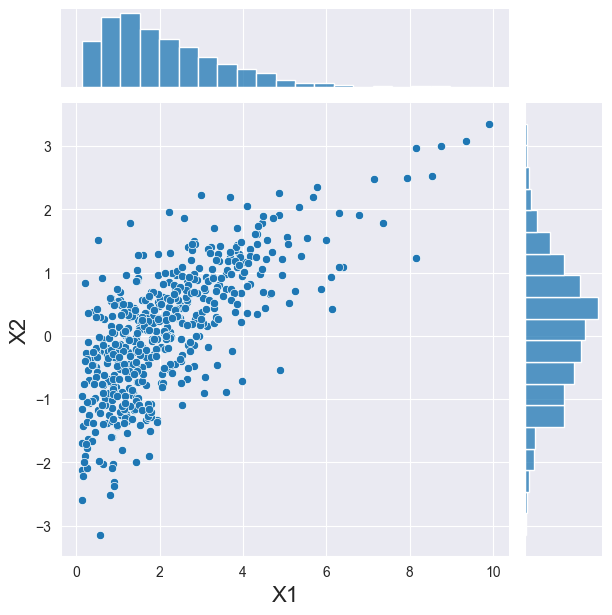
ここで注意すべき点が2つあります。(i) 独立の場合と同様に、周辺分布が正しくガンマ分布と正規分布を示していること。(ii) 2つの変数間に依存関係が見られることです。
[ ]:
コピュラパラメータの推定¶
ここでは、実験データが既にあり、Gumbelコピュラを使用して依存関係を表現できることが分かっているとします。しかし、コピュラのハイパーパラメータの値が分かりません。この場合、その値を推定することができます。
今回は、生成したサンプルを使用します。このサンプルでは、得られるべきハイパーパラメータの値が既知であり、それはtheta=2です。
[7]:
copula = GumbelCopula()
theta = copula.fit_corr_param(sample)
print(theta)
2.049379621506455
推定されたハイパーパラメーターの値が、以前に設定した値に近いことが分かります。