線形混合効果モデル¶
[1]:
%matplotlib inline
import numpy as np
import pandas as pd
import statsmodels.api as sm
import statsmodels.formula.api as smf
from statsmodels.tools.sm_exceptions import ConvergenceWarning
注:このノートブックの R コードと結果はマークダウンに変換されているため、ドキュメントの作成にRは必要ありません。ノートブックのR結果は、R 3.5.1 と lme4 1.1を使用して計算されました。
%load_ext rpy2.ipython
%R library(lme4)
array(['lme4', 'Matrix', 'tools', 'stats', 'graphics', 'grDevices',
'utils', 'datasets', 'methods', 'base'], dtype='<U9')
R の lmer と statsmodels の MixedLM の比較¶
statsmodels の線形混合モデル(MixedLM)の実装は、Lindstrom と Bates(JASA 1988)で概説されたアプローチに密接に従っています。これはRパッケージLME4でも採用されているアプローチです。Stata や SAS などの他のパッケージも、このアプローチに一致しているはずです。なぜなら、この分野の基本的な手法はほとんど成熟しているからです。
ここでは、statsmodels の MixedLM 手続きを使用して線形混合モデルをフィットさせる方法を示します。比較のために R(LME4)からの結果も含まれています。
以下がインポートしたステートメントです:
豚の成長曲線¶
これは因子実験からの縦断データです。結果変数は各豚の体重で、ここで使用する唯一の予測変数は「時間」です。まず、各豚に対してランダム切片を持つ時間の線形関数として平均体重を表現するモデルをフィットさせます。このモデルは、数式を使用して指定されます。ランダム効果の構造が指定されていないため、デフォルトのランダム効果構造(各グループに対するランダム切片)が自動的に使用されます。
[2]:
data = sm.datasets.get_rdataset("dietox", "geepack").data
md = smf.mixedlm("Weight ~ Time", data, groups=data["Pig"])
mdf = md.fit(method=["lbfgs"])
print(mdf.summary())
Mixed Linear Model Regression Results
========================================================
Model: MixedLM Dependent Variable: Weight
No. Observations: 861 Method: REML
No. Groups: 72 Scale: 11.3669
Min. group size: 11 Log-Likelihood: -2404.7753
Max. group size: 12 Converged: Yes
Mean group size: 12.0
--------------------------------------------------------
Coef. Std.Err. z P>|z| [0.025 0.975]
--------------------------------------------------------
Intercept 15.724 0.788 19.952 0.000 14.179 17.268
Time 6.943 0.033 207.939 0.000 6.877 7.008
Group Var 40.395 2.149
========================================================
以下は、LMER を使用して R でフィットした同じモデルです:
%%R
data(dietox, package='geepack')
%R print(summary(lmer('Weight ~ Time + (1|Pig)', data=dietox)))
Linear mixed model fit by REML ['lmerMod']
Formula: Weight ~ Time + (1 | Pig)
Data: dietox
REML criterion at convergence: 4809.6
Scaled residuals:
Min 1Q Median 3Q Max
-4.7118 -0.5696 -0.0943 0.4877 4.7732
Random effects:
Groups Name Variance Std.Dev.
Pig (Intercept) 40.39 6.356
Residual 11.37 3.371
Number of obs: 861, groups: Pig, 72
Fixed effects:
Estimate Std. Error t value
(Intercept) 15.72352 0.78805 19.95
Time 6.94251 0.03339 207.94
Correlation of Fixed Effects:
(Intr)
Time -0.275
統計モデルの結果のサマリーでは、固定効果とランダム効果のパラメータ推定値が 1 つの表に示されています。上記の statsmodels の出力では、動物に対するランダム効果は「Intercept RE」としてラベル付けされています。LME4 の出力では、この効果はランダム効果のセクションにおける豚のインタセプト(切片)です。
ランダム効果の分散と共分散パラメータの標準誤差が有用かどうかについては多くの議論があります。LME4では、これらの標準誤差は表示されません。なぜなら、このパッケージの著者たちは、標準誤差があまり有益ではないと考えているからです。これらの有用性に疑問を呈する理由は十分にありますが、我々はサマリー表に標準誤差を含めることにしました。ただし、対応するウォルド信頼区間は表示しません。
次に、各動物に対して2つのランダム効果(ランダム切片とランダム傾き:時間に関する)を持つモデルをフィットさせます。これは、各豚が異なる基準体重を持ち、異なる成長速度で成長することを意味します。式は「Time」がランダム係数を持つ共変量であることを指定します。デフォルトでは、式には常にインタセプトが含まれています(ここでは「0 + Time」として式を指定することでインタセプトを抑制することもできます)。
[3]:
md = smf.mixedlm("Weight ~ Time", data, groups=data["Pig"], re_formula="~Time")
mdf = md.fit(method=["lbfgs"])
print(mdf.summary())
Mixed Linear Model Regression Results
===========================================================
Model: MixedLM Dependent Variable: Weight
No. Observations: 861 Method: REML
No. Groups: 72 Scale: 6.0372
Min. group size: 11 Log-Likelihood: -2217.0475
Max. group size: 12 Converged: Yes
Mean group size: 12.0
-----------------------------------------------------------
Coef. Std.Err. z P>|z| [0.025 0.975]
-----------------------------------------------------------
Intercept 15.739 0.550 28.603 0.000 14.660 16.817
Time 6.939 0.080 86.925 0.000 6.783 7.095
Group Var 19.503 1.561
Group x Time Cov 0.294 0.153
Time Var 0.416 0.033
===========================================================
以下は、R で LMER を使用して同じモデルをフィットしたものです:
%R print(summary(lmer("Weight ~ Time + (1 + Time | Pig)", data=dietox)))
Linear mixed model fit by REML ['lmerMod']
Formula: Weight ~ Time + (1 + Time | Pig)
Data: dietox
REML criterion at convergence: 4434.1
Scaled residuals:
Min 1Q Median 3Q Max
-6.4286 -0.5529 -0.0416 0.4841 3.5624
Random effects:
Groups Name Variance Std.Dev. Corr
Pig (Intercept) 19.493 4.415
Time 0.416 0.645 0.10
Residual 6.038 2.457
Number of obs: 861, groups: Pig, 72
Fixed effects:
Estimate Std. Error t value
(Intercept) 15.73865 0.55012 28.61
Time 6.93901 0.07982 86.93
Correlation of Fixed Effects:
(Intr)
Time 0.006
ランダム切片とランダム傾きは、ほとんど相関していません(\(0.294 / \sqrt{19.493 * 0.416} \approx 0.1\))。したがって、次に、2つのランダム効果が相関しないように制約を課したモデルをフィットさせます。
[4]:
0.294 / (19.493 * 0.416) ** 0.5
[4]:
0.10324316832591753
[5]:
md = smf.mixedlm("Weight ~ Time", data, groups=data["Pig"], re_formula="~Time")
free = sm.regression.mixed_linear_model.MixedLMParams.from_components(
np.ones(2), np.eye(2)
)
mdf = md.fit(free=free, method=["lbfgs"])
print(mdf.summary())
Mixed Linear Model Regression Results
===========================================================
Model: MixedLM Dependent Variable: Weight
No. Observations: 861 Method: REML
No. Groups: 72 Scale: 6.0283
Min. group size: 11 Log-Likelihood: -2217.3481
Max. group size: 12 Converged: Yes
Mean group size: 12.0
-----------------------------------------------------------
Coef. Std.Err. z P>|z| [0.025 0.975]
-----------------------------------------------------------
Intercept 15.739 0.554 28.388 0.000 14.652 16.825
Time 6.939 0.080 86.248 0.000 6.781 7.097
Group Var 19.837 1.571
Group x Time Cov 0.000 0.000
Time Var 0.423 0.033
===========================================================
相関パラメータを 0 に固定すると、尤度は 0.3 低下します。 2 x 0.3 = 0.6 を自由度1のカイ二乗分布と比較すると、このパラメータが 0 であるモデルとデータは非常に一致していることが示唆されます。
こちらは R の LMER を使用して同じモデルをフィットさせた結果です(ここではRが尤度の代わりにREML基準を報告していることに注意してください。REML 基準は尤度の2倍です)。
%R print(summary(lmer("Weight ~ Time + (1 | Pig) + (0 + Time | Pig)", data=dietox)))
Linear mixed model fit by REML ['lmerMod']
Formula: Weight ~ Time + (1 | Pig) + (0 + Time | Pig)
Data: dietox
REML criterion at convergence: 4434.7
Scaled residuals:
Min 1Q Median 3Q Max
-6.4281 -0.5527 -0.0405 0.4840 3.5661
Random effects:
Groups Name Variance Std.Dev.
Pig (Intercept) 19.8404 4.4543
Pig.1 Time 0.4234 0.6507
Residual 6.0282 2.4552
Number of obs: 861, groups: Pig, 72
Fixed effects:
Estimate Std. Error t value
(Intercept) 15.73875 0.55444 28.39
Time 6.93899 0.08045 86.25
Correlation of Fixed Effects:
(Intr)
Time -0.086
シトカの成長データ¶
これは、LMER Rライブラリで提供されているデータセットの例の1つです。結果変数はツリーのサイズであり、ここで使用される共変量は時間値です。データはツリーによってグループ化されます。
[6]:
data = sm.datasets.get_rdataset("Sitka", "MASS").data
endog = data["size"]
data["Intercept"] = 1
exog = data[["Intercept", "Time"]]
以下は、ランダム切片を持つ基本モデルにフィットする statsmodels LME です。endog と exog のデータを配列として LME init 関数に直接渡しています。また、endog_re は引数 4 でランダム切片として明示的に指定されていることにも注意してください(指定されていない場合はデフォルトになります)。
[7]:
md = sm.MixedLM(endog, exog, groups=data["tree"], exog_re=exog["Intercept"])
mdf = md.fit()
print(mdf.summary())
Mixed Linear Model Regression Results
=======================================================
Model: MixedLM Dependent Variable: size
No. Observations: 395 Method: REML
No. Groups: 79 Scale: 0.0392
Min. group size: 5 Log-Likelihood: -82.3884
Max. group size: 5 Converged: Yes
Mean group size: 5.0
-------------------------------------------------------
Coef. Std.Err. z P>|z| [0.025 0.975]
-------------------------------------------------------
Intercept 2.273 0.088 25.864 0.000 2.101 2.446
Time 0.013 0.000 47.796 0.000 0.012 0.013
Intercept Var 0.374 0.345
=======================================================
以下は、LMER を使用して R でフィットした同じモデルです:
%R
data(Sitka, package="MASS")
print(summary(lmer("size ~ Time + (1 | tree)", data=Sitka)))
Linear mixed model fit by REML ['lmerMod']
Formula: size ~ Time + (1 | tree)
Data: Sitka
REML criterion at convergence: 164.8
Scaled residuals:
Min 1Q Median 3Q Max
-2.9979 -0.5169 0.1576 0.5392 4.4012
Random effects:
Groups Name Variance Std.Dev.
tree (Intercept) 0.37451 0.612
Residual 0.03921 0.198
Number of obs: 395, groups: tree, 79
Fixed effects:
Estimate Std. Error t value
(Intercept) 2.2732443 0.0878955 25.86
Time 0.0126855 0.0002654 47.80
Correlation of Fixed Effects:
(Intr)
Time -0.611
次に、ランダムな勾配を追加してみましょう。今回は R から始めます。次のコードと出力から、ランダムな勾配の分散の REML 推定値がほぼ 0 であることがわかります。
%R print(summary(lmer("size ~ Time + (1 + Time | tree)", data=Sitka)))
Linear mixed model fit by REML ['lmerMod']
Formula: size ~ Time + (1 + Time | tree)
Data: Sitka
REML criterion at convergence: 153.4
Scaled residuals:
Min 1Q Median 3Q Max
-2.7609 -0.5173 0.1188 0.5270 3.5466
Random effects:
Groups Name Variance Std.Dev. Corr
tree (Intercept) 2.217e-01 0.470842
Time 3.288e-06 0.001813 -0.17
Residual 3.634e-02 0.190642
Number of obs: 395, groups: tree, 79
Fixed effects:
Estimate Std. Error t value
(Intercept) 2.273244 0.074655 30.45
Time 0.012686 0.000327 38.80
Correlation of Fixed Effects:
(Intr)
Time -0.615
convergence code: 0
Model failed to converge with max|grad| = 0.793203 (tol = 0.002, component 1)
Model is nearly unidentifiable: very large eigenvalue
- Rescale variables?
これをデフォルトでstatsmodels LMEで実行すると、分散推定値が実際に非常に小さいことがわかり、解がパラメータ空間の境界上にあるという警告が表示されます。回帰勾配は R と非常によく一致しますが、尤度値は R によって返される値よりもはるかに高くなります。
[8]:
exog_re = exog.copy()
md = sm.MixedLM(endog, exog, data["tree"], exog_re)
mdf = md.fit()
print(mdf.summary())
Mixed Linear Model Regression Results
===============================================================
Model: MixedLM Dependent Variable: size
No. Observations: 395 Method: REML
No. Groups: 79 Scale: 0.0264
Min. group size: 5 Log-Likelihood: -62.4834
Max. group size: 5 Converged: Yes
Mean group size: 5.0
---------------------------------------------------------------
Coef. Std.Err. z P>|z| [0.025 0.975]
---------------------------------------------------------------
Intercept 2.273 0.101 22.513 0.000 2.075 2.471
Time 0.013 0.000 33.888 0.000 0.012 0.013
Intercept Var 0.646 0.914
Intercept x Time Cov -0.001 0.003
Time Var 0.000 0.000
===============================================================
C:\Users\user\projects\statsmodels\venv\lib\site-packages\statsmodels\regression\mixed_linear_model.py:2237: ConvergenceWarning: The MLE may be on the boundary of the parameter space.
warnings.warn(msg, ConvergenceWarning)
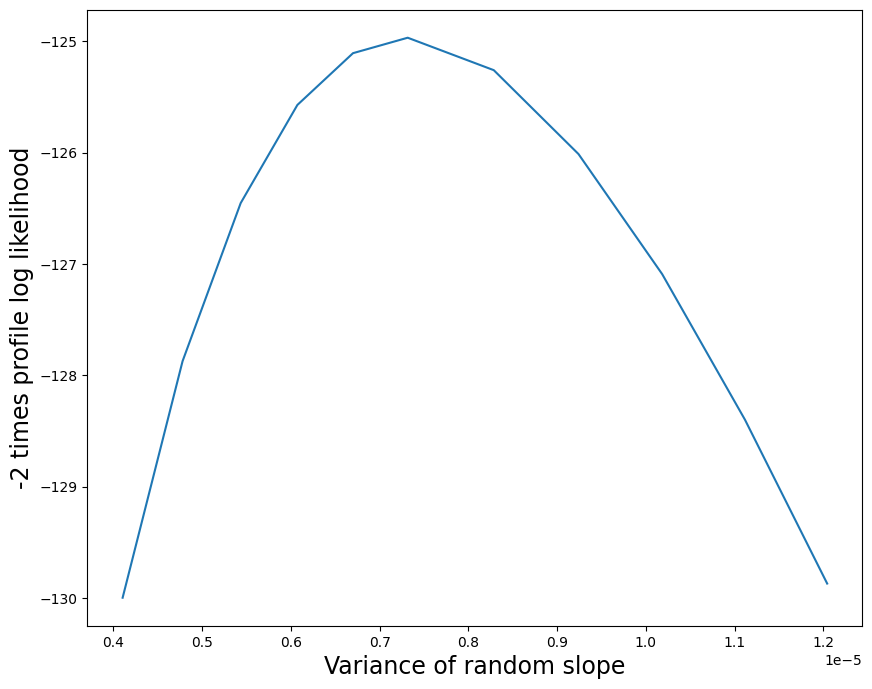
プロファイル尤度のプロットを構築することによって、ランダム効果構造をさらに調べることができます。ランダム切片から始めて、MLEの下 0.1 単位から上 0.1 単位までのプロファイル尤度のプロットを生成します。プロファイル尤度内の各最適化は警告を生成するため(ランダム勾配分散が0に近いため)、ここでは警告をオフにします。
[9]:
import warnings
with warnings.catch_warnings():
warnings.filterwarnings("ignore")
likev = mdf.profile_re(0, "re", dist_low=0.1, dist_high=0.1)
こちらはプロファイル尤度関数のプロットです。対数尤度の差を 2 倍して、1 自由度の通常の \(\chi^2\) 参照分布を得ています。
[10]:
import matplotlib.pyplot as plt
[11]:
plt.figure(figsize=(10, 8))
plt.plot(likev[:, 0], 2 * likev[:, 1])
plt.xlabel("Variance of random intercept", size=17)
plt.ylabel("-2 times profile log likelihood", size=17)
[11]:
Text(0, 0.5, '-2 times profile log likelihood')
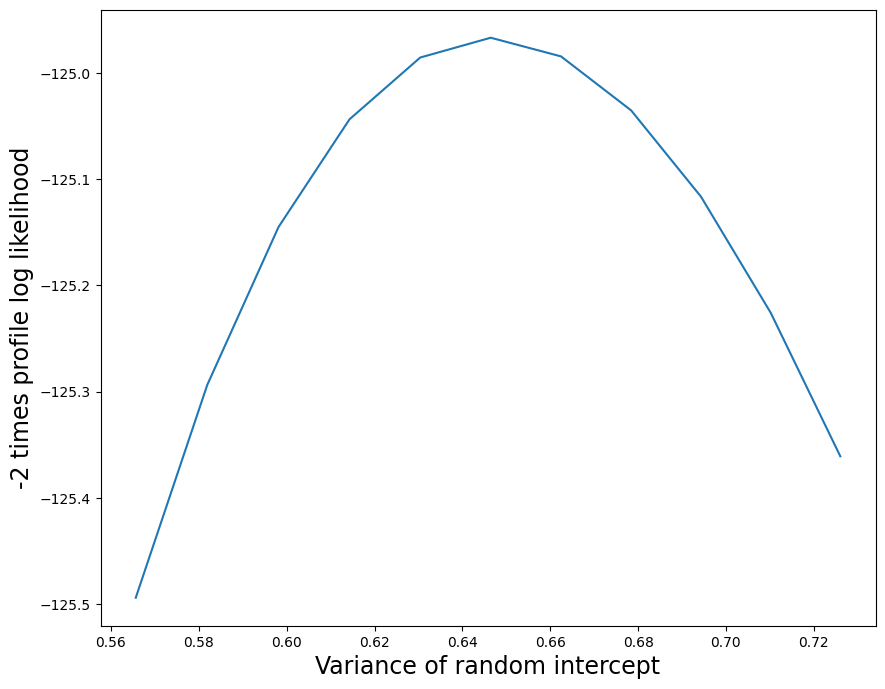
これはプロファイル尤度関数のプロットです。プロファイル尤度プロットは、ランダム勾配分散パラメータのMLEが非常に小さな正数であり、この推定値には低い不確実性があることを示しています。
[12]:
re = mdf.cov_re.iloc[1, 1]
with warnings.catch_warnings():
# Parameter is often on the boundary
warnings.simplefilter("ignore", ConvergenceWarning)
likev = mdf.profile_re(1, "re", dist_low=0.5 * re, dist_high=0.8 * re)
plt.figure(figsize=(10, 8))
plt.plot(likev[:, 0], 2 * likev[:, 1])
plt.xlabel("Variance of random slope", size=17)
lbl = plt.ylabel("-2 times profile log likelihood", size=17)