SARIMAX と ARIMA: よくある質問 (FAQ)¶
このノートブックには、よくある質問への説明が含まれています。
SARIMAX、ARIMA、およびAutoRegにおけるトレンドと外生変数の比較SARIMAXとARIMAにおける残差、適合度、予測の再構成SARIMAXとARIMAにおける初期残差
SARIMAX、ARIMA、およびAutoRegにおけるトレンドと外生変数の比較¶
ARIMAは形式的にはARMA誤差を持つOLSです。OLSにおける基本的なAR(1)モデルは次のように記述されます。
大きな標本では、\(\hat{\delta}\stackrel{p}{\rightarrow} E[Y]\)となります。
SARIMAXは異なる表現を使用しており、SARIMAXを使用して推定されたモデルは次のようになります。
これは、OLS(AutoReg)を使用してモデルを推定する際に使用される表現と同じです。大きな標本では、\(\hat{\phi}\stackrel{p}{\rightarrow} E[Y](1-\rho)\)となります。
次のセルでは、大きな標本をシミュレーションし、これらの関係が実際に成立するかどうかを確認します。
[1]:
%matplotlib inline
[2]:
import numpy as np
import pandas as pd
rng = np.random.default_rng(20210819)
eta = rng.standard_normal(5200)
rho = 0.8
beta = 10
epsilon = eta.copy()
for i in range(1, eta.shape[0]):
epsilon[i] = rho * epsilon[i - 1] + eta[i]
y = beta + epsilon
y = y[200:]
[3]:
from statsmodels.tsa.api import SARIMAX, AutoReg
from statsmodels.tsa.arima.model import ARIMA
次のセルで、3つのモデルが指定され、推定されます。AR(0)は参照として含まれています。AR(0)は、3つの推定量を使用して同一です。
[4]:
ar0_res = SARIMAX(y, order=(0, 0, 0), trend="c").fit()
sarimax_res = SARIMAX(y, order=(1, 0, 0), trend="c").fit()
arima_res = ARIMA(y, order=(1, 0, 0), trend="c").fit()
autoreg_res = AutoReg(y, 1, trend="c").fit()
以下の表には、モデルの推定パラメータ、推定されたAR(1)係数、および長期的な平均が含まれています。長期的な平均は、推定パラメータ(AR(0)またはARIMA)と等しいか、または切片の比率と1からAR(1)パラメータを引いた値に依存します。
[5]:
intercept = [
ar0_res.params[0],
sarimax_res.params[0],
arima_res.params[0],
autoreg_res.params[0],
]
rho_hat = [0] + [r.params[1] for r in (sarimax_res, arima_res, autoreg_res)]
long_run = [
ar0_res.params[0],
sarimax_res.params[0] / (1 - sarimax_res.params[1]),
arima_res.params[0],
autoreg_res.params[0] / (1 - autoreg_res.params[1]),
]
cols = ["AR(0)", "SARIMAX", "ARIMA", "AutoReg"]
pd.DataFrame(
[intercept, rho_hat, long_run],
columns=cols,
index=["delta-or-phi", "rho", "long-run mean"],
)
[5]:
| AR(0) | SARIMAX | ARIMA | AutoReg | |
|---|---|---|---|---|
| delta-or-phi | 9.7745 | 1.985714 | 9.774498 | 1.985790 |
| rho | 0.0000 | 0.796846 | 0.796875 | 0.796882 |
| long-run mean | 9.7745 | 9.774424 | 9.774498 | 9.776537 |
SARIMAXにおけるトレンドと外生変数(exog)の違い¶
SARIMAX に外生変数(exog)を含む場合、exog はOLS回帰変数として扱われ、その結果、推定されるモデルは次のようになります。
次の例では、トレンドを省略し、代わりに1の列を含めることで、外生回帰変数がなく、trend="c" の場合と同等のモデルを生成します。ここで、const の推定値は、ARIMA を使用した場合の推定値と一致します。これは、SARIMAX の外生変数と ARIMA のトレンドの両方が、ARMA誤差を持つ線形回帰モデルとして扱われるためです。
[6]:
sarimax_exog_res = SARIMAX(y, exog=np.ones_like(y), order=(1, 0, 0), trend="n").fit()
print(sarimax_exog_res.summary())
SARIMAX Results
==============================================================================
Dep. Variable: y No. Observations: 5000
Model: SARIMAX(1, 0, 0) Log Likelihood -7068.656
Date: Wed, 28 Aug 2024 AIC 14143.311
Time: 14:57:28 BIC 14162.863
Sample: 0 HQIC 14150.164
- 5000
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
const 9.7745 0.069 141.177 0.000 9.639 9.910
ar.L1 0.7969 0.009 93.691 0.000 0.780 0.814
sigma2 0.9894 0.020 49.921 0.000 0.951 1.028
===================================================================================
Ljung-Box (L1) (Q): 0.42 Jarque-Bera (JB): 0.08
Prob(Q): 0.51 Prob(JB): 0.96
Heteroskedasticity (H): 0.97 Skew: -0.01
Prob(H) (two-sided): 0.47 Kurtosis: 2.99
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
SARIMAX と ARIMA における exog の使用¶
exog は両方のモデルで同様に扱われますが、切片は依然として異なります。以下では、y に外生回帰変数を加え、3つの方法すべてを使用してモデルをフィットさせます。データ生成過程は以下のようになります。
[7]:
full_x = rng.standard_normal(eta.shape)
x = full_x[200:]
y += 3 * x
[8]:
sarimax_exog_res = SARIMAX(y, exog=x, order=(1, 0, 0), trend="c").fit()
arima_exog_res = ARIMA(y, exog=x, order=(1, 0, 0), trend="c").fit()
パラメータテーブルを確認すると、x1 のパラメータ推定値は同一である一方で、intercept の推定値はこれらの推定量におけるトレンドの取り扱いの違いにより引き続き異なっています。
SARIMAX¶
[9]:
def print_params(s):
from io import StringIO
return pd.read_csv(StringIO(s.tables[1].as_csv()), index_col=0)
print_params(sarimax_exog_res.summary())
[9]:
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| intercept | 1.9849 | 0.085 | 23.484 | 0.0 | 1.819 | 2.151 |
| x1 | 3.0231 | 0.011 | 277.150 | 0.0 | 3.002 | 3.044 |
| ar.L1 | 0.7969 | 0.009 | 93.735 | 0.0 | 0.780 | 0.814 |
| sigma2 | 0.9886 | 0.020 | 49.941 | 0.0 | 0.950 | 1.027 |
ARIMA¶
[10]:
print_params(arima_exog_res.summary())
[10]:
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 9.7741 | 0.069 | 141.201 | 0.0 | 9.638 | 9.910 |
| x1 | 3.0231 | 0.011 | 277.140 | 0.0 | 3.002 | 3.044 |
| ar.L1 | 0.7969 | 0.009 | 93.728 | 0.0 | 0.780 | 0.814 |
| sigma2 | 0.9886 | 0.020 | 49.941 | 0.0 | 0.950 | 1.027 |
AutoRegにおけるexog(外生変数)¶
AutoRegを使用してOLSでモデルを推定する場合、このモデルはSARIMAXやARIMAのモデルとは異なります。外生変数を含むAutoRegの仕様は以下のようになります。
この仕様は、SARIMAXやARIMAで推定される仕様とは同等ではありません。ここでの違いは単純ではなく、同じ時系列データで単純な推定を行った場合、パラメータ値が異なる結果となります。大きな標本(およびその極限)でも異なる結果が得られます。このモデルを推定すると、AR(1)係数のパラメータ推定値が変化します。
AutoReg¶
[11]:
autoreg_exog_res = AutoReg(y, 1, exog=x, trend="c").fit()
print_params(autoreg_exog_res.summary())
[11]:
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 7.9714 | 0.064 | 124.525 | 0.0 | 7.846 | 8.097 |
| y.L1 | 0.1838 | 0.006 | 29.890 | 0.0 | 0.172 | 0.196 |
| x1 | 3.0311 | 0.021 | 142.513 | 0.0 | 2.989 | 3.073 |
このモデルをラグ演算子記法で表現すると、重要な違いが見て取れます。
ここで、\(|\phi|<1\) と仮定しています。ここで見るべき点は、\(Y_t\) が \(X_t\) と \(\eta_t\) のすべての遅延値に依存しているということです。これは SARIMAX や ARIMA によって推定される仕様とは異なり、以下のように表現できます。
この仕様では、\(Y_t\) は \(X_t\) のみに依存し、他の遅延値には依存しません。
AutoRegを使用した正しいDGPの適用¶
AutoRegで推定されるプロセスをシミュレーションすると、パラメータが真のモデルから回収されることがわかります。
[12]:
y = beta + eta
epsilon = eta.copy()
for i in range(1, eta.shape[0]):
y[i] = beta * (1 - rho) + rho * y[i - 1] + 3 * full_x[i] + eta[i]
y = y[200:]
正しいDGPを用いたAutoReg¶
[13]:
autoreg_alt_exog_res = AutoReg(y, 1, exog=x, trend="c").fit()
print_params(autoreg_alt_exog_res.summary())
[13]:
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 1.9870 | 0.030 | 66.526 | 0.0 | 1.928 | 2.046 |
| y.L1 | 0.7968 | 0.003 | 300.382 | 0.0 | 0.792 | 0.802 |
| x1 | 3.0263 | 0.014 | 217.034 | 0.0 | 2.999 | 3.054 |
SARIMAX および ARIMA における残差、適合度、予測値の再構築¶
自己回帰項、トレンド、外生変数のみを含むモデルでは、モデルで最大のラグ長が達成されると、適合度と予測値を容易に再構築することができます。実際には、これは \((P+D)s+p+d\) の期間後を意味します。それ以前の予測値や残差は再構築が難しくなります。なぜなら、モデルは \(Y_t|Y_{t-1},Y_{t-2},...\) に基づいて最適な予測を構築するためです。もし \(Y\) のラグ数が自己回帰次数より少ない場合、最適な予測の式はモデルと異なります。例えば、最初の値 \(Y_1\) を予測する場合、\(Y\)
の履歴から情報は得られないため、最適な予測は無条件の平均となります。AR(1) の場合、2回目の予測はモデルに従い、ARIMA を使用すると予測は次のようになります。
これは、ARIMA が外生変数およびトレンド項をARMA誤差を伴う回帰として扱うためです。
この動作は次のセルで確認できます。
[14]:
arima_res = ARIMA(y, order=(1, 0, 0), trend="c").fit()
print_params(arima_res.summary())
[14]:
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 9.9346 | 0.222 | 44.667 | 0.0 | 9.499 | 10.371 |
| ar.L1 | 0.7957 | 0.009 | 92.515 | 0.0 | 0.779 | 0.813 |
| sigma2 | 10.3015 | 0.204 | 50.496 | 0.0 | 9.902 | 10.701 |
[15]:
arima_res.predict(0, 2)
[15]:
array([ 9.93458658, 10.91088035, 11.80415747])
[16]:
delta_hat, rho_hat = arima_res.params[:2]
delta_hat + rho_hat * (y[0] - delta_hat)
[16]:
10.91088034623065
SARIMAXはトレンド項を異なる方法で扱うため、SARIMAXを使用して推定したモデルからの1ステップ予測は次のようになります。
[17]:
sarima_res = SARIMAX(y, order=(1, 0, 0), trend="c").fit()
print_params(sarima_res.summary())
[17]:
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| intercept | 2.0283 | 0.097 | 20.841 | 0.0 | 1.838 | 2.219 |
| ar.L1 | 0.7959 | 0.009 | 92.536 | 0.0 | 0.779 | 0.813 |
| sigma2 | 10.3007 | 0.204 | 50.500 | 0.0 | 9.901 | 10.700 |
[18]:
sarima_res.predict(0, 2)
[18]:
array([ 9.93588659, 10.91128867, 11.80469658])
[19]:
delta_hat, rho_hat = sarima_res.params[:2]
delta_hat + rho_hat * y[0]
[19]:
10.911288670867208
MA成分を含む予測¶
モデルにMA成分が含まれている場合、誤差は直接観測できないため、予測はより複雑になります。予測は依然として\(Y_t|Y_{t-1},Y_{t-2},...\)であり、MA成分が逆転可能な場合、最適な予測は\(t\)ラグAR過程として表現できます。\(t\)が大きい場合、これは誤差が観測可能であるかのような予測に非常に近いはずです。しかし、短いラグの場合、この予測は大きく異なることがあります。
次のセルでは、MA(1)過程をシミュレートし、MAモデルをフィットさせます。
[20]:
rho = 0.8
beta = 10
epsilon = eta.copy()
for i in range(1, eta.shape[0]):
epsilon[i] = rho * eta[i - 1] + eta[i]
y = beta + epsilon
y = y[200:]
ma_res = ARIMA(y, order=(0, 0, 1), trend="c").fit()
print_params(ma_res.summary())
[20]:
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 9.9185 | 0.025 | 391.129 | 0.0 | 9.869 | 9.968 |
| ma.L1 | 0.8025 | 0.009 | 93.864 | 0.0 | 0.786 | 0.819 |
| sigma2 | 0.9904 | 0.020 | 49.925 | 0.0 | 0.951 | 1.029 |
標本の初めに対応する予測、すなわち y[1] から y[5] を最初に見ていきます。
[21]:
ma_res.predict(1, 5)
[21]:
array([ 8.57011015, 9.19907188, 8.96971353, 9.78987115, 11.11984478])
そして、」直接的」予測を作成するために必要な対応する残差
[22]:
ma_res.resid[:5]
[22]:
array([-2.7621904 , -1.12255005, -1.33557621, -0.17206944, 1.5634041 ])
モデルパラメータを使用して、MA(1)仕様に基づく「直接的」な予測を生成できます。
最初の予測では、これらが実際のモデル予測と特に近いわけではありませんが、そのギャップは迅速に縮小することがわかります。
[23]:
delta_hat, rho_hat = ma_res.params[:2]
direct = delta_hat + rho_hat * ma_res.resid[:5]
direct
[23]:
array([ 7.70168405, 9.01756049, 8.84659855, 9.7803589 , 11.17314527])
最初はその差はほぼ標準偏差に相当しますが、インデックスが増加するにつれて減少します。
[24]:
ma_res.predict(1, 5) - direct
[24]:
array([ 0.8684261 , 0.18151139, 0.12311499, 0.00951225, -0.05330049])
次に、標本の最後と最後の 3 つの予測を見てみましょう。
[25]:
t = y.shape[0]
ma_res.predict(t - 3, t - 1)
[25]:
array([ 9.79692804, 10.51272714, 10.55855562])
[26]:
ma_res.resid[-4:-1]
[26]:
array([-0.15142355, 0.74049384, 0.79759816])
[27]:
direct = delta_hat + rho_hat * ma_res.resid[-4:-1]
direct
[27]:
array([ 9.79692804, 10.51272714, 10.55855562])
「直接」 予測は同一です。これは、短い標本の影響が標本の終わりまでに消えているために起こります (実際には、観測値 100 程度では無視できるほど小さく、観測値 160 程度では数値的に存在しなくなります)。
[28]:
ma_res.predict(t - 3, t - 1) - direct
[28]:
array([0., 0., 0.])
同じ原則は、複数のラグや季節項を含むより複雑なモデルにも当てはまります。AR モデルの予測は、有効なラグの長さに達すると簡単になりますが、MA コンポーネントを含むモデルの予測は、MA ラグ多項式の最大根が十分に小さくなり、残差が真の残差に近くなると簡単になります。
SARIMAX と ARIMA の予測の違い¶
SARIMAX と ARIMA モデルを使った予測で使用される数式には、重要な違いがあります。具体的には、ARIMA はすべてのトレンド項(例えば、切片や時間トレンド)を外生回帰変数の一部として扱います。例えば、ARIMA を用いて推定された切片と線形時間トレンドを持つ AR(1) モデルの仕様は以下のようになります。
同じモデルが SARIMAX を使って推定される場合、仕様は次のようになります。
外生回帰変数 \(X_t\) が含まれる場合、違いはより明確になります。ARIMA の仕様は次の通りです。
一方、SARIMAX の仕様は次の通りです。
これらの違いの重要な点は、切片とトレンドが ARIMA では外生回帰変数として扱われるのに対し、SARIMAX では標準的な ARMA 項のように扱われるということです。
次のセルでは、ARIMA の仕様を用いて時間トレンドを持つ ARX モデルをシミュレートし、両方の推定方法を使ってパラメータを推定します。
[29]:
rho = 0.8
beta = 2
delta0 = 10
delta1 = 0.5
epsilon = eta.copy()
for i in range(1, eta.shape[0]):
epsilon[i] = rho * epsilon[i - 1] + eta[i]
t = np.arange(epsilon.shape[0])
y = delta0 + delta1 * t + beta * full_x + epsilon
y = y[200:]
[30]:
start = np.array([110, delta1, beta, rho, 1])
arx_res = ARIMA(y, exog=x, order=(1, 0, 0), trend="ct").fit()
mod = SARIMAX(y, exog=x, order=(1, 0, 0), trend="ct")
start[:2] *= 1 - rho
sarimax_res = mod.fit(start_params=start, method="bfgs")
Current function value: 1.413691
Iterations: 43
Function evaluations: 72
Gradient evaluations: 62
C:\Users\user\projects\statsmodels\venv\lib\site-packages\scipy\optimize\_optimize.py:1291: OptimizeWarning: Desired error not necessarily achieved due to precision loss.
res = _minimize_bfgs(f, x0, args, fprime, callback=callback, **opts)
C:\Users\user\projects\statsmodels\venv\lib\site-packages\statsmodels\base\model.py:607: ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals
warnings.warn("Maximum Likelihood optimization failed to "
二つの推定量は似たようにフィットしていますが、対数尤度にわずかな違いがあります。これは数値的な問題であり、予測に実質的な影響を与えることはないはずです。重要なのは、二つのトレンドパラメータである const と x1(残念ながら時間トレンドとして名前が付けられています)が異なる点です。それ以外のパラメータは実質的に同一です。
[31]:
print(arx_res.summary())
SARIMAX Results
==============================================================================
Dep. Variable: y No. Observations: 5000
Model: ARIMA(1, 0, 0) Log Likelihood -7069.171
Date: Wed, 28 Aug 2024 AIC 14148.343
Time: 14:57:34 BIC 14180.928
Sample: 0 HQIC 14159.763
- 5000
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
const 109.2112 0.137 796.186 0.000 108.942 109.480
x1 0.5000 4.78e-05 1.05e+04 0.000 0.500 0.500
x2 2.0495 0.011 187.517 0.000 2.028 2.071
ar.L1 0.7965 0.009 93.669 0.000 0.780 0.813
sigma2 0.9897 0.020 49.854 0.000 0.951 1.029
===================================================================================
Ljung-Box (L1) (Q): 0.33 Jarque-Bera (JB): 0.15
Prob(Q): 0.57 Prob(JB): 0.93
Heteroskedasticity (H): 0.97 Skew: -0.01
Prob(H) (two-sided): 0.53 Kurtosis: 3.00
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
[32]:
print(sarimax_res.summary())
SARIMAX Results
==============================================================================
Dep. Variable: y No. Observations: 5000
Model: SARIMAX(1, 0, 0) Log Likelihood -7068.457
Date: Wed, 28 Aug 2024 AIC 14146.914
Time: 14:57:34 BIC 14179.500
Sample: 0 HQIC 14158.335
- 5000
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
intercept 22.7438 0.929 24.481 0.000 20.923 24.565
drift 0.1019 0.004 23.985 0.000 0.094 0.110
x1 2.0230 0.011 185.290 0.000 2.002 2.044
ar.L1 0.7963 0.008 93.745 0.000 0.780 0.813
sigma2 0.9894 0.020 49.899 0.000 0.951 1.028
===================================================================================
Ljung-Box (L1) (Q): 0.47 Jarque-Bera (JB): 0.13
Prob(Q): 0.49 Prob(JB): 0.94
Heteroskedasticity (H): 0.97 Skew: -0.01
Prob(H) (two-sided): 0.47 Kurtosis: 3.00
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
初期残差 SARIMAX と ARIMA¶
最大モデルの順序(AR、MA、季節的AR、季節的MA、差分のパラメータに依存する)より前の観測値の残差は信頼性が低く、性能評価には使用すべきではありません。一般的に、ARIMAモデルでの順序\((p,d,q)\times(P,D,Q,s)\)の場合、残差がうまく振る舞わない場合の公式は次の通りです:
ARIMA(1,0,0)(1,0,0,12)からいくつかのデータをシミュレートし、残差を調べてみましょう。
[33]:
import numpy as np
import pandas as pd
rho = 0.8
psi = -0.6
beta = 20
epsilon = eta.copy()
for i in range(13, eta.shape[0]):
epsilon[i] = (
rho * epsilon[i - 1]
+ psi * epsilon[i - 12]
- (rho * psi) * epsilon[i - 13]
+ eta[i]
)
y = beta + epsilon
y = y[200:]
大規模な標本では、パラメータ推定値はDGP(データ生成過程)のパラメータに非常に近くなります。
[34]:
res = ARIMA(y, order=(1, 0, 0), trend="c", seasonal_order=(1, 0, 0, 12)).fit()
print(res.summary())
SARIMAX Results
========================================================================================
Dep. Variable: y No. Observations: 5000
Model: ARIMA(1, 0, 0)x(1, 0, 0, 12) Log Likelihood -7076.266
Date: Wed, 28 Aug 2024 AIC 14160.532
Time: 14:57:35 BIC 14186.600
Sample: 0 HQIC 14169.668
- 5000
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
const 19.8586 0.043 458.609 0.000 19.774 19.943
ar.L1 0.7972 0.008 93.925 0.000 0.781 0.814
ar.S.L12 -0.6044 0.011 -53.280 0.000 -0.627 -0.582
sigma2 0.9914 0.020 49.899 0.000 0.952 1.030
===================================================================================
Ljung-Box (L1) (Q): 0.50 Jarque-Bera (JB): 0.11
Prob(Q): 0.48 Prob(JB): 0.95
Heteroskedasticity (H): 0.96 Skew: -0.01
Prob(H) (two-sided): 0.40 Kurtosis: 2.99
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
まず、モデル内の実際のショックに対してプロットすることで、最初の 13 個の残差を調べることができます。対応関係はあるものの、その関係はかなり弱く、相関は 1 よりはるかに小さくなります。
[35]:
import matplotlib.pyplot as plt
plt.rc("figure", figsize=(10, 10))
plt.rc("font", size=14)
_ = plt.scatter(res.resid[:13], eta[200 : 200 + 13])
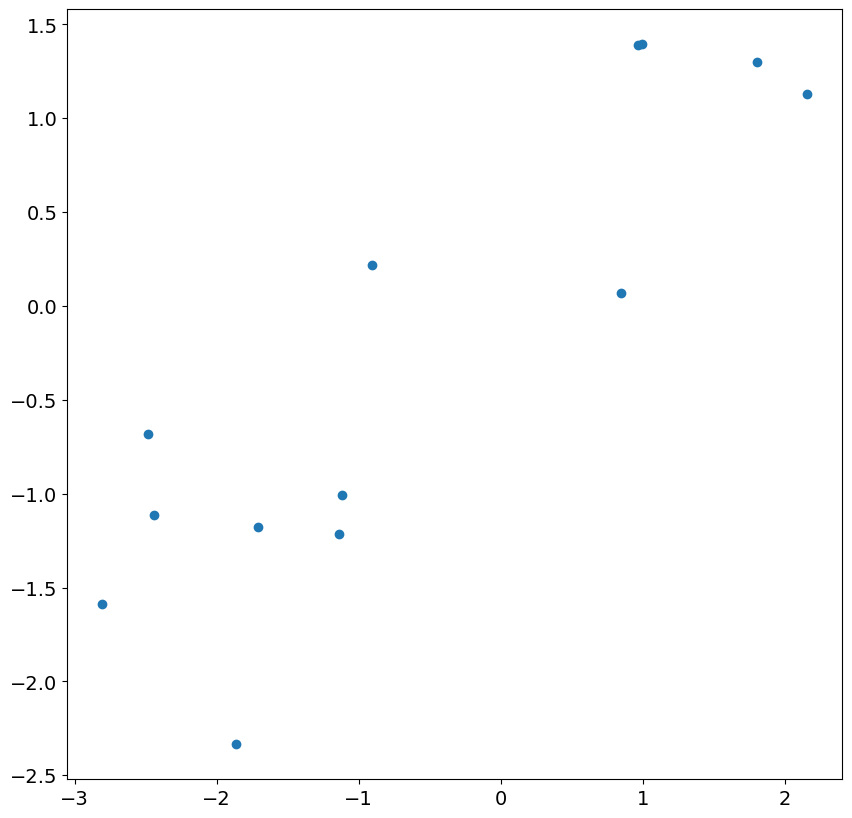
次の 24 の残差とショックを見ると、ほぼ完璧な相関関係があることがわかります。これは、精度の低い残差を無視すれば、大規模な標本では予想される結果です。
[36]:
_ = plt.scatter(res.resid[13:37], eta[200 + 13 : 200 + 37])
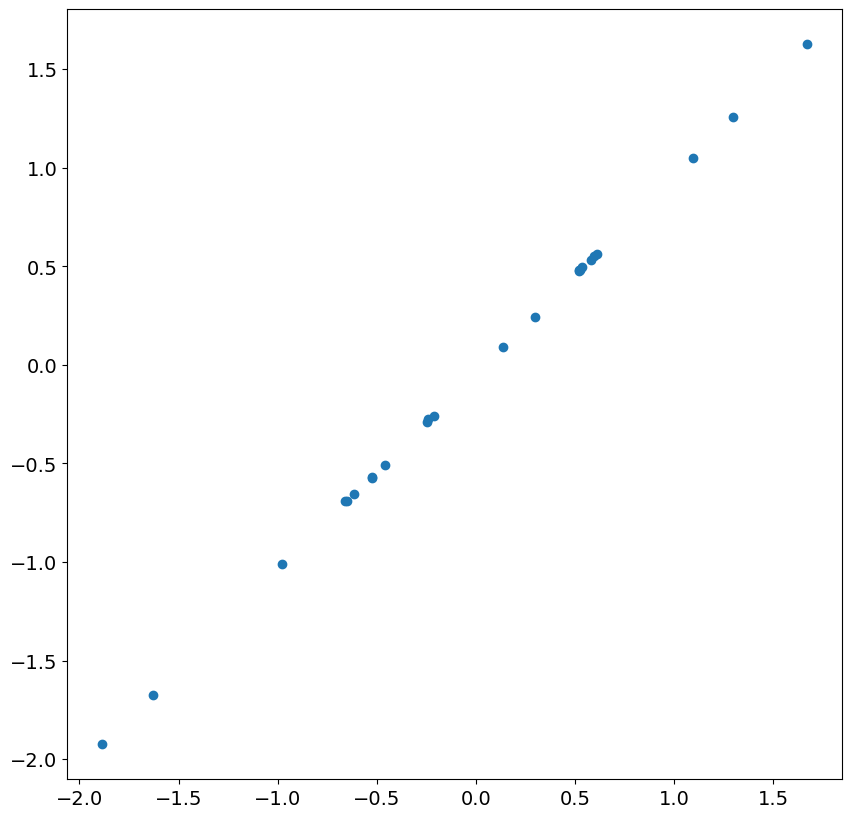
次に、ARIMA(1,1,0)をシミュレートし、時間トレンドを含めます。
[37]:
rng = np.random.default_rng(20210819)
eta = rng.standard_normal(5200)
rho = 0.8
beta = 20
epsilon = eta.copy()
for i in range(2, eta.shape[0]):
epsilon[i] = (1 + rho) * epsilon[i - 1] - rho * epsilon[i - 2] + eta[i]
t = np.arange(epsilon.shape[0])
y = beta + 2 * t + epsilon
y = y[200:]
ここでも、パラメータ推定値は DGP パラメータに非常に近いです。
[38]:
res = ARIMA(y, order=(1, 1, 0), trend="t").fit()
print(res.summary())
SARIMAX Results
==============================================================================
Dep. Variable: y No. Observations: 5000
Model: ARIMA(1, 1, 0) Log Likelihood -7067.739
Date: Wed, 28 Aug 2024 AIC 14141.479
Time: 14:57:36 BIC 14161.030
Sample: 0 HQIC 14148.331
- 5000
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
x1 1.7747 0.069 25.642 0.000 1.639 1.910
ar.L1 0.7968 0.009 93.658 0.000 0.780 0.813
sigma2 0.9896 0.020 49.908 0.000 0.951 1.028
===================================================================================
Ljung-Box (L1) (Q): 0.43 Jarque-Bera (JB): 0.09
Prob(Q): 0.51 Prob(JB): 0.96
Heteroskedasticity (H): 0.97 Skew: -0.01
Prob(H) (two-sided): 0.47 Kurtosis: 2.99
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
残差は正確ではなく、最初の残差は約 500 です。他の残差はより近いですが、このモデルでは通常、最初の 2 つは無視されます。
[39]:
res.resid[:5]
[39]:
array([ 5.08403002e+02, -1.58904197e+00, -1.54902445e+00, 1.04992619e-01,
1.33644383e+00])
最初の残差が非常に大きい理由は、この値の最適な予測が差の平均、つまり 1.77 であるためです。最初の値がわかると、2 番目の値は最初の値を予測に利用し、予測は事実にかなり近くなります。
[40]:
res.predict(0, 5)
[40]:
array([ 1.77472562, 511.95355128, 510.87392196, 508.85708934,
509.03356182, 511.85245439])
結果クラスには、どの残差が問題となっているかを理解するのに役立つ2つのパラメータが含まれていることに注目する価値があります。loglikelihood_burn と nobs_diffuse です。
[41]:
res.loglikelihood_burn, res.nobs_diffuse
[41]:
(1, 0)