トレンド除去、スタイライズド・ファクト、及び景気循環¶
影響力のある記事で、Harvey と Jaeger(1993)は、景気循環のスタイライズド・ファクトを導き出すために、未観測成分モデル(「構造時系列モデル」とも呼ばれる)の使用について説明しました。
彼らの論文は次のように始まります:
「一連の時系列に関連する『スタイライズド・ファクト』の確立は、マクロ経済学研究において広く重要なステップと見なされています… これらの事実が有用であるためには、(1) データの確率的特性と一致していること、(2) 意味のある情報を提供することが求められます。」
特に、彼らは、これらの目標を達成するためには、人気のあるホドリック・プレスコットフィルタやボックス=ジェンキンスのARIMAモデリング技法よりも、未観測成分アプローチを使用する方がしばしば優れていると主張しています。
statsmodels には、これらの三種類の分析を実行する能力があり、以下では彼らの論文の手順に従い、少し更新されたデータセットを使用します。
[1]:
%matplotlib inline
import numpy as np
import pandas as pd
import statsmodels.api as sm
import matplotlib.pyplot as plt
from IPython.display import display, Latex
未観測成分(Unobserved Components)¶
statsmodelsで利用できる観測されない成分モデルは、次のように記述できます:
記法と追加の詳細については、Durbin と Koopman 2012年の第3章を参照してください。異なる個々の成分に対する異なる仕様が広範なモデルをサポートすることに注意してください。以下の論文で考慮された特定のモデルは、この一般的な方程式の特殊な形です。
トレンド¶
トレンド成分は、切片と線形時間トレンドを含む回帰モデルの動的拡張です。
ここで、レベルは切片項の一般化であり、時間とともに動的に変動することができます。トレンドは時間トレンドの一般化であり、傾きが時間とともに動的に変動することができます。
両方の要素(レベルとトレンド)について、以下のようなモデルを考慮することができます:
要素が含まれているか、除外されているか(トレンドが含まれている場合、レベルも含まれていなければならない)。
要素が決定的か、確率的か(つまり、誤差項の分散がゼロに制限されているかどうか)。
最大尤度法(MLE)で推定する必要があるのは、含まれている確率的な成分の分散です。
以下のような仕様が導かれます:
レベル |
トレンド |
確率的レベル |
確率的トレンド |
|
|---|---|---|---|---|
定数 |
✓ |
|||
ローカルレベル (ランダムウォーク) |
✓ |
✓ |
||
決定論的トレンド |
✓ |
✓ |
||
ローカルレベルと決定論的トレンド (ドリフト付きランダムウォーク) |
✓ |
✓ |
✓ |
|
ローカル線形トレンド |
✓ |
✓ |
✓ |
✓ |
スムーズトレンド (積分ランダムウォーク) |
✓ |
✓ |
✓ |
季節性¶
季節性成分は次のように書かれます:
周期性(季節の数)はsであり、特徴的なのは(誤差項がない場合)季節成分が1つの完全なサイクルでゼロに合計されることです。誤差項を含めることで、季節効果が時間とともに変動することが可能になります。
このモデルの変種は以下の通りです:
周期性
s季節効果を確率的にするかどうか
もし季節効果が確率的であれば、最大尤度法(MLE)で推定する必要がある1つの追加パラメータ(誤差項の分散)が存在します。
サイクル¶
サイクル成分は、季節成分で捉えられない長期的なサイクル効果を捉えることを目的としています。例えば、経済学ではサイクル項は通常、景気循環を捉えるために使われ、その周期は「1.5年から12年」の間と予測されます(Durbin と Koopmanを参照)。
サイクルは次のように書かれます:
パラメータ\(\lambda_c\)(サイクルの周波数)はMLEによって推定される追加のパラメータです。もし季節効果が確率的であれば、さらに1つのパラメータ(誤差項の分散)を推定する必要があります。
不規則成分¶
不規則成分は、ホワイトノイズ誤差項として仮定されます。その分散はMLEによって推定するパラメータです;すなわち、
場合によっては、不規則成分を自己回帰効果を許容するように一般化したいことがあります:
この場合、自己回帰パラメータもMLEによって推定されます。
回帰効果¶
説明変数を含めるために追加の項を含めたい場合:
または介入効果を含める場合:
これらの追加パラメータは、MLEで推定するか、状態空間モデルの成分として含めることができます。
データ¶
ハーヴィーとイェーガーに従い、以下の時系列データを考察します:
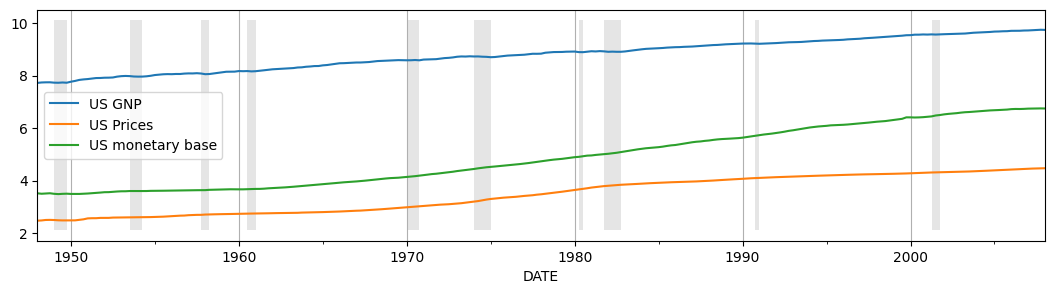
元々の論文では、時系列ごとに期間が異なりますが、おおよそ1954年から1989年の範囲でした。ここでは、すべての時系列に対して1948年から2008年の期間を使用します。未観測成分アプローチによりモデル内で季節成分を分離することが可能ですが、論文で考慮されたデータ系列、及びここで使用されるデータ系列はすでに季節調整済みです。
ここで考慮するすべてのデータ系列は連邦準備制度経済データ(FRED)から取得されています。便利なことに、PythonライブラリのpandasはFREDから直接データをダウンロードする機能を提供しています。
[2]:
# Datasets
from pandas_datareader.data import DataReader
# Get the raw data
start = '1948-01'
end = '2008-01'
us_gnp = DataReader('GNPC96', 'fred', start=start, end=end)
us_gnp_deflator = DataReader('GNPDEF', 'fred', start=start, end=end)
us_monetary_base = DataReader('AMBSL', 'fred', start=start, end=end).resample('QS').mean()
recessions = DataReader('USRECQ', 'fred', start=start, end=end).resample('QS').last().values[:,0]
# Construct the dataframe
dta = pd.concat(map(np.log, (us_gnp, us_gnp_deflator, us_monetary_base)), axis=1)
dta.columns = ['US GNP','US Prices','US monetary base']
dta.index.freq = dta.index.inferred_freq
dates = dta.index._mpl_repr()
これらの3つの変数の時間軸に沿った傾向を把握するために、プロットしてみましょう。
[3]:
# Plot the data
ax = dta.plot(figsize=(13,3))
ylim = ax.get_ylim()
ax.xaxis.grid()
ax.fill_between(dates, ylim[0]+1e-5, ylim[1]-1e-5, recessions, facecolor='k', alpha=0.1);
モデル¶
データはすでに季節調整されており、明確な説明変数はないため、考慮される一般的なモデルは次の通りです:
不規則項はホワイトノイズであると仮定し、サイクルは確率的で減衰するものとします。最終的なモデル選択は、トレンド成分に使用する仕様です。Harvey と Jaeger は、次の2つのモデルを検討しています:
ローカル線形トレンド(「制限なし」モデル)
スムーズトレンド(「制限あり」モデル、\(\sigma_\eta = 0\) を強制しているため)
以下では、これらのモデルタイプそれぞれに対して kwargs 辞書を作成します。モデルを指定する方法には2通りあることに注意してください。一つは、上記の表のように成分を直接指定する方法です。もう一つは、さまざまな仕様にマッピングされる文字列名を使用する方法です。
[4]:
# Model specifications
# Unrestricted model, using string specification
unrestricted_model = {
'level': 'local linear trend', 'cycle': True, 'damped_cycle': True, 'stochastic_cycle': True
}
# Unrestricted model, setting components directly
# This is an equivalent, but less convenient, way to specify a
# local linear trend model with a stochastic damped cycle:
# unrestricted_model = {
# 'irregular': True, 'level': True, 'stochastic_level': True, 'trend': True, 'stochastic_trend': True,
# 'cycle': True, 'damped_cycle': True, 'stochastic_cycle': True
# }
# The restricted model forces a smooth trend
restricted_model = {
'level': 'smooth trend', 'cycle': True, 'damped_cycle': True, 'stochastic_cycle': True
}
# Restricted model, setting components directly
# This is an equivalent, but less convenient, way to specify a
# smooth trend model with a stochastic damped cycle. Notice
# that the difference from the local linear trend model is that
# `stochastic_level=False` here.
# unrestricted_model = {
# 'irregular': True, 'level': True, 'stochastic_level': False, 'trend': True, 'stochastic_trend': True,
# 'cycle': True, 'damped_cycle': True, 'stochastic_cycle': True
# }
以下のモデルを適合させます:
生産、制約なしのモデル
価格、制約なしのモデル
価格、制約ありのモデル
マネー、制約なしのモデル
マネー、制約ありのモデル
[5]:
# Output
output_mod = sm.tsa.UnobservedComponents(dta['US GNP'], **unrestricted_model)
output_res = output_mod.fit(method='powell', disp=False)
# Prices
prices_mod = sm.tsa.UnobservedComponents(dta['US Prices'], **unrestricted_model)
prices_res = prices_mod.fit(method='powell', disp=False)
prices_restricted_mod = sm.tsa.UnobservedComponents(dta['US Prices'], **restricted_model)
prices_restricted_res = prices_restricted_mod.fit(method='powell', disp=False)
# Money
money_mod = sm.tsa.UnobservedComponents(dta['US monetary base'], **unrestricted_model)
money_res = money_mod.fit(method='powell', disp=False)
money_restricted_mod = sm.tsa.UnobservedComponents(dta['US monetary base'], **restricted_model)
money_restricted_res = money_restricted_mod.fit(method='powell', disp=False)
これらのモデルを適合させた後、情報を表示する方法はいくつかあります。米国GNPのモデルを見てみると、適合したモデルの概要は、フィットオブジェクトのsummaryメソッドを使用して要約できます。
[6]:
print(output_res.summary())
Unobserved Components Results
=====================================================================================
Dep. Variable: US GNP No. Observations: 241
Model: local linear trend Log Likelihood 769.972
+ damped stochastic cycle AIC -1527.945
Date: Sat, 23 Mar 2024 BIC -1507.137
Time: 10:53:04 HQIC -1519.558
Sample: 01-01-1948
- 01-01-2008
Covariance Type: opg
====================================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------------
sigma2.irregular 1.398e-06 7.35e-06 0.190 0.849 -1.3e-05 1.58e-05
sigma2.level 2.777e-06 4.97e-05 0.056 0.955 -9.47e-05 0.000
sigma2.trend 3.199e-06 1.48e-06 2.162 0.031 2.98e-07 6.1e-06
sigma2.cycle 3.872e-05 2.55e-05 1.517 0.129 -1.13e-05 8.87e-05
frequency.cycle 0.4496 0.047 9.544 0.000 0.357 0.542
damping.cycle 0.8671 0.042 20.559 0.000 0.784 0.950
===================================================================================
Ljung-Box (L1) (Q): 0.00 Jarque-Bera (JB): 9.27
Prob(Q): 1.00 Prob(JB): 0.01
Heteroskedasticity (H): 0.26 Skew: -0.04
Prob(H) (two-sided): 0.00 Kurtosis: 3.96
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
未観測成分モデル、特に序論のポイント(2)に沿ったスタイライズされた事実を探る際には、推定された未観測成分(例えば、レベル、トレンド、サイクル)をプロットすることで、データの意味のある説明を提供するかどうかを確認する方が、しばしば有益です。
plot_components メソッドを使用すると、各推定された状態のプロットと信頼区間を表示でき、また観測データとモデルの1ステップ先予測をプロットして適合度を評価することもできます。
[7]:
fig = output_res.plot_components(legend_loc='lower right', figsize=(15, 9));
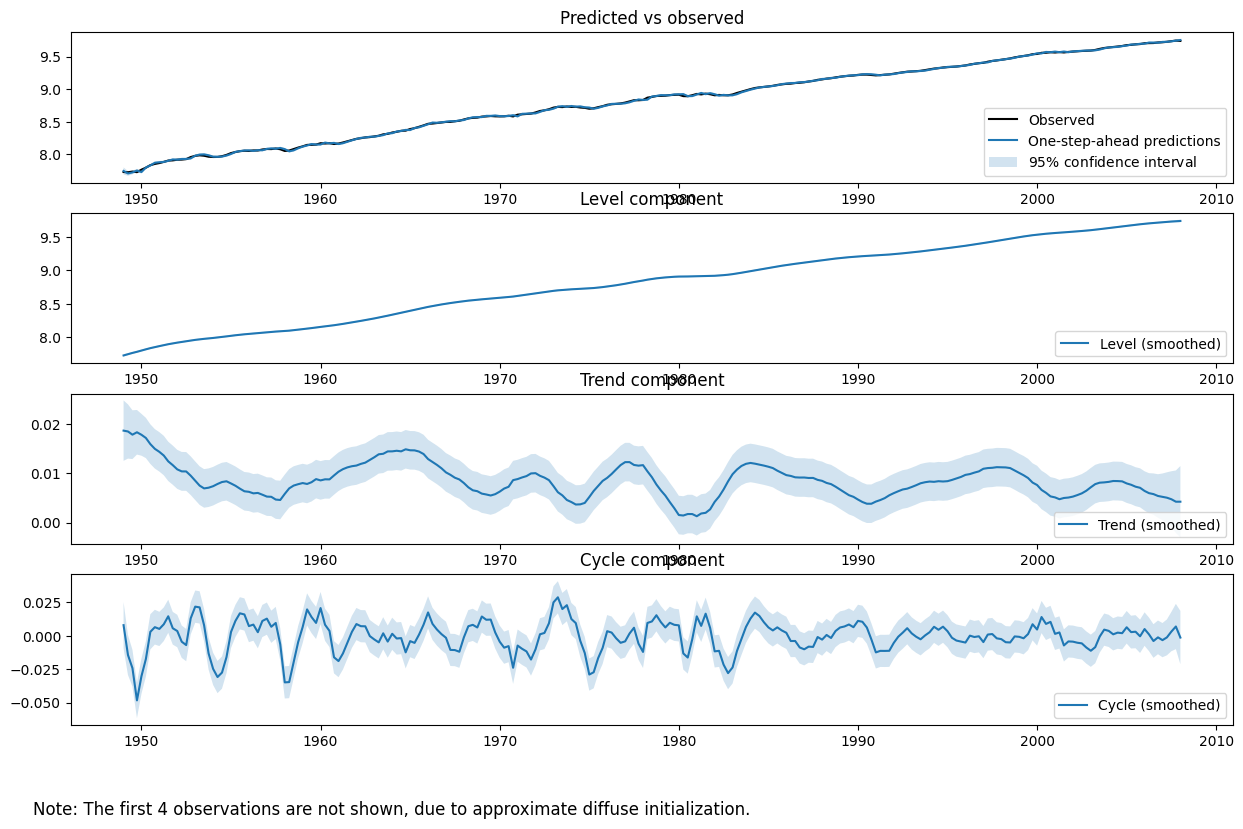
最後に、HarveyとJaegerは、トレンド成分と循環成分の相対的重要性を強調するために、別の方法でモデルを要約しています。以下に、私たちは彼らの表Iを再現します。私たちが得た値は、おおむね一致していますが、詳細には彼らの表の値とは異なります。
[8]:
# Create Table I
table_i = np.zeros((5,6))
start = dta.index[0]
end = dta.index[-1]
time_range = '%d:%d-%d:%d' % (start.year, start.quarter, end.year, end.quarter)
models = [
('US GNP', time_range, 'None'),
('US Prices', time_range, 'None'),
('US Prices', time_range, r'$\sigma_\eta^2 = 0$'),
('US monetary base', time_range, 'None'),
('US monetary base', time_range, r'$\sigma_\eta^2 = 0$'),
]
index = pd.MultiIndex.from_tuples(models, names=['Series', 'Time range', 'Restrictions'])
parameter_symbols = [
r'$\sigma_\zeta^2$', r'$\sigma_\eta^2$', r'$\sigma_\kappa^2$', r'$\rho$',
r'$2 \pi / \lambda_c$', r'$\sigma_\varepsilon^2$',
]
i = 0
for res in (output_res, prices_res, prices_restricted_res, money_res, money_restricted_res):
if res.model.stochastic_level:
(sigma_irregular, sigma_level, sigma_trend,
sigma_cycle, frequency_cycle, damping_cycle) = res.params
else:
(sigma_irregular, sigma_level,
sigma_cycle, frequency_cycle, damping_cycle) = res.params
sigma_trend = np.nan
period_cycle = 2 * np.pi / frequency_cycle
table_i[i, :] = [
sigma_level*1e7, sigma_trend*1e7,
sigma_cycle*1e7, damping_cycle, period_cycle,
sigma_irregular*1e7
]
i += 1
pd.set_option('float_format', lambda x: '%.4g' % np.round(x, 2) if not np.isnan(x) else '-')
table_i = pd.DataFrame(table_i, index=index, columns=parameter_symbols)
table_i
[8]:
| $\sigma_\zeta^2$ | $\sigma_\eta^2$ | $\sigma_\kappa^2$ | $\rho$ | $2 \pi / \lambda_c$ | $\sigma_\varepsilon^2$ | |||
|---|---|---|---|---|---|---|---|---|
| Series | Time range | Restrictions | ||||||
| US GNP | 1948:1-2008:1 | None | 27.77 | 31.99 | 387.2 | 0.87 | 13.98 | 13.98 |
| US Prices | 1948:1-2008:1 | None | 0 | 61.89 | 20.7 | 0.43 | 6.55 | 0 |
| $\sigma_\eta^2 = 0$ | 61.91 | NaN | 20.7 | 0.43 | 6.55 | 0 | ||
| US monetary base | 1948:1-2008:1 | None | 69.41 | 18.77 | 192.6 | 0.89 | 23.25 | 0 |
| $\sigma_\eta^2 = 0$ | 18.83 | NaN | 247.9 | 0.89 | 23.92 | 0 |